ColinWikholm BIOL368 Week 15
Purpose
To learn microarray and data analysis techniques, apply this knowledge to study of relevant literature, and apply learned skills to analyze gene expression data of gene deletion mutants of yeast.
Microarray Data Analysis
Before you begin: Turn on File Extensions
- The Windows 7 operating systems defaults to hiding file extensions. To turn them back on, do the following:
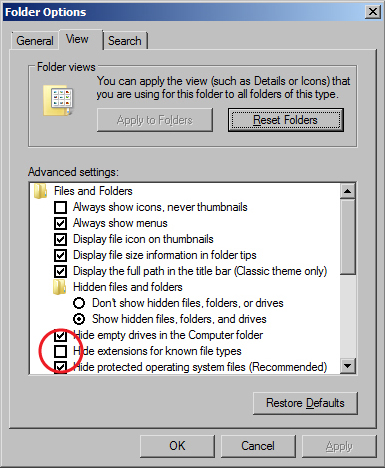
Folder Options window - Go to the Start menu and select "Control Panel".
- In the window that appears, search for "Folder Options" in the search field in the upper right hand corner.
- Click on "Folder Options" in the main window.
- When the Folder Options window appears, click on the View tab.
- Uncheck the box for "Hide extensions for known file types".
- Click the OK button.
- The computers in Seaver 120 are are set to erase all custom user settings and restore the defaults once they have been restarted, so if you have done this previously, you might have to do it again.

Experimental Design
Recall from last week's lecture, there were five timepoints in the experiment that were competitively hybridized with the t0 sample:
- t15 (cold shock)
- t30 (cold shock)
- t60 (cold shock)
- t90 (recovery)
- t120 (recovery)
Each timepoint has 3-5 independent replicates.
Note that the Δswi4 strain does not have a t15 timepoint and begins with t30.
Within-strain ANOVA
The purpose of the within-stain ANOVA test is to determine if any genes had a gene expression change that was significantly different than zero at any timepoint.
- Create a new worksheet, naming it either "dswi4_ANOVA" as appropriate. For example, you might call yours "wt_ANOVA" or "dHAP4_ANOVA"
- Copy the first three columns containing the "Master_Index", "ID", and "Standard_Name" from the "Master_Sheet" worksheet for your strain and paste it into your new worksheet. Copy the columns containing the data for your strain and paste it into your new worksheet.
- At the top of the first column to the right of your data, create five column headers of the form dswi4_AvgLogFC_(TIME) where dswi4 is your strain designation and (TIME) is 30, 60 etc.
- In the cell below the dswi4_AvgLogFC_t30 header, type
=AVERAGE( - Then highlight all the data in row 2 associated with dswi4 and t30, press the closing paren key (shift 0),and press the "enter" key.
- This cell now contains the average of the log fold change data from the first gene at t=30 minutes.
- Click on this cell and position your cursor at the bottom right corner. You should see your cursor change to a thin black plus sign (not a chubby white one). When it does, double click, and the formula will magically be copied to the entire column of 6188 other genes.
- Repeat steps (4) through (8) with the t30, t60, t90, and the t120 data.
- Now in the first empty column to the right of the dswi4_AvgLogFC_t120 calculation, create the column header dswi4_ss_HO.
- In the first cell below this header, type
=SUMSQ( - Highlight all the LogFC data in row 2 for your dswi4 (but not the AvgLogFC), press the closing paren key (shift 0),and press the "enter" key.
- In the next empty column to the right of dswi4_ss_HO, create the column headers dswi4_ss_(TIME) as in (3).
- Make a note of how many data points you have at each time point for your strain. For most of the strains, it will be 4, but for dHAP4 t90 or t120, it will be "3", and for the wild type it will be "4" or "5". Count carefully. Also, make a note of the total number of data points. Again, for most strains, this will be 20, but for example, dHAP4, this number will be 18, and for wt it should be 23 (double-check).
- In the first cell below the header dswi4_ss_t30, type
=SUMSQ(<range of cells for logFC_t30>)-<number of data points>*<AvgLogFC_t30>^2and hit enter.- The phrase <range of cells for logFC_t30> should be replaced by the data range associated with t30.
- The phrase <number of data points> should be replaced by the number of data points for that timepoint (either 3, 4, or 5).
- The phrase <AvgLogFC_t30> should be replaced by the cell number in which you computed the AvgLogFC for t30, and the "^2" squares that value.
- Upon completion of this single computation, use the Step (7) trick to copy the formula throughout the column.
- Repeat this computation for the t30 through t120 data points. Again, be sure to get the data for each time point, type the right number of data points, and get the average from the appropriate cell for each time point, and copy the formula to the whole column for each computation.
- In the first column to the right of dswi4_ss_t120, create the column header dswi4_SS_full.
- In the first row below this header, type
=sum(<range of cells containing "ss" for each timepoint>)and hit enter. - In the next two columns to the right, create the headers dswi4_Fstat and dswi4_p-value.
- Recall the number of data points from (13): call that total n.
- In the first cell of the dswi4_Fstat column, type
=((n-5)/5)*(<dswi4_ss_HO>-<dswi4_SS_full>)/<dswi4_SS_full>and hit enter.- Don't actually type the n but instead use the number from (13). Also note that "5" is the number of timepoints and the dSWI4 strain has 4 timepoints (it is missing t30).
- Replace the phrase dswi4_ss_HO with the cell designation.
- Replace the phrase <dswi4_SS_full> with the cell designation.
- Copy to the whole column.
- In the first cell below the dswi4_p-value header, type
=FDIST(<dswi4_Fstat>,5,n-5)replacing the phrase <dswi4_Fstat> with the cell designation and the "n" as in (13) with the number of data points total. (Again, note that the number of timepoints is actually "4" for the dSWI4 strain). Copy to the whole column. - Before we move on to the next step, we will perform a quick sanity check to see if we did all of these computations correctly.
- Click on cell A1 and click on the Data tab. Select the Filter icon (looks like a funnel). Little drop-down arrows should appear at the top of each column. This will enable us to filter the data according to criteria we set.
- Click on the drop-down arrow on your dswi4_p-value column. Select "Number Filters". In the window that appears, set a criterion that will filter your data so that the p value has to be less than 0.05.
- Excel will now only display the rows that correspond to data meeting that filtering criterion. A number will appear in the lower left hand corner of the window giving you the number of rows that meet that criterion. We will check our results with each other to make sure that the computations were performed correctly.
Calculate the Bonferroni and p value Correction
- Now we will perform adjustments to the p value to correct for the multiple testing problem. Label the next two columns to the right with the same label, dswi4_Bonferroni_p-value.
- Type the equation
=<dswi4_p-value>*6189, Upon completion of this single computation, use the Step (10) trick to copy the formula throughout the column. - Replace any corrected p value that is greater than 1 by the number 1 by typing the following formula into the first cell below the second dswi4_Bonferroni_p-value header:
=IF(r2>1,1,r2). Use the Step (10) trick to copy the formula throughout the column.
Calculate the Benjamini & Hochberg p value Correction
- Insert a new worksheet named "dswi4_ANOVA_B-H".
- Copy and paste the "Master_Index", "ID", and "Standard_Name" columns from your previous worksheet into the first two columns of the new worksheet.
- For the following, use Paste special > Paste values. Copy your unadjusted p values from your ANOVA worksheet and paste it into Column D.
- Select all of columns A, B, C, and D. Sort by ascending values on Column D. Click the sort button from A to Z on the toolbar, in the window that appears, sort by column D, smallest to largest.
- Type the header "Rank" in cell E1. We will create a series of numbers in ascending order from 1 to 6189 in this column. This is the p value rank, smallest to largest. Type "1" into cell E2 and "2" into cell E3. Select both cells E2 and E3. Double-click on the plus sign on the lower right-hand corner of your selection to fill the column with a series of numbers from 1 to 6189.
- Now you can calculate the Benjamini and Hochberg p value correction. Type dswi4_B-H_p-value in cell F1. Type the following formula in cell F2:
=(D2*6189)/E2and press enter. Copy that equation to the entire column. - Type "dswi4_B-H_p-value" into cell G1.
- Type the following formula into cell G2:
=IF(F2>1,1,F2)and press enter. Copy that equation to the entire column. - Select columns A through G. Now sort them by your Master_Index in Column A in ascending order.
- Copy column G and use Paste special > Paste values to paste it into the next column on the right of your ANOVA sheet.
Sanity Check: Number of genes significantly changed
Before we move on to further analysis of the data, we want to perform a more extensive sanity check to make sure that we performed our data analysis correctly. We are going to find out the number of genes that are significantly changed at various p value cut-offs.
- Go to your dswi4_ANOVA worksheet.
- Select row 1 (the row with your column headers) and select the menu item Data > Filter > Autofilter (The funnel icon on the Data tab). Little drop-down arrows should appear at the top of each column. This will enable us to filter the data according to criteria we set.
- Click on the drop-down arrow for the unadjusted p value. Set a criterion that will filter your data so that the p value has to be less than 0.05.
- How many genes have p < 0.05? and what is the percentage (out of 6189)?
- 2782 (45.0%)
- How many genes have p < 0.01? and what is the percentage (out of 6189)?
- 1837 (29.7%)
- How many genes have p < 0.001? and what is the percentage (out of 6189)?
- 977 (15.8%)
- How many genes have p < 0.0001? and what is the percentage (out of 6189)?
- 522 (8.43%)
- How many genes have p < 0.05? and what is the percentage (out of 6189)?
- When we use a p value cut-off of p < 0.05, what we are saying is that you would have seen a gene expression change that deviates this far from zero by chance less than 5% of the time.
- We have just performed 6189 hypothesis tests. Another way to state what we are seeing with p < 0.05 is that we would expect to see this a gene expression change for at least one of the timepoints by chance in about 5% of our tests, or 309 times. Since we have more than 309 genes that pass this cut off, we know that some genes are significantly changed. However, we don't know which ones. To apply a more stringent criterion to our p values, we performed the Bonferroni and Benjamini and Hochberg corrections to these unadjusted p values. The Bonferroni correction is very stringent. The Benjamini-Hochberg correction is less stringent. To see this relationship, filter your data to determine the following:
- How many genes are p < 0.05 for the Bonferroni-corrected p value? and what is the percentage (out of 6189)?
- 224 (3.62%)
- How many genes are p < 0.05 for the Benjamini and Hochberg-corrected p value? and what is the percentage (out of 6189)?
- 2080 (33.6%)
- How many genes are p < 0.05 for the Bonferroni-corrected p value? and what is the percentage (out of 6189)?
- In summary, the p value cut-off should not be thought of as some magical number at which data becomes "significant". Instead, it is a moveable confidence level. If we want to be very confident of our data, use a small p value cut-off. If we are OK with being less confident about a gene expression change and want to include more genes in our analysis, we can use a larger p value cut-off.
- Comparing results with known data: the expression of the gene NSR1 (ID: YGR159C)is known to be induced by cold shock. Find NSR1 in your dataset. What is its unadjusted, Bonferroni-corrected, and B-H-corrected p values? What is its average Log fold change at each of the timepoints in the experiment? Note that the average Log fold change is what we called "(dswi4)_AvgLogFC_(TIME)" in step 3 of the ANOVA analysis.
- The unadjusted, Bonferroni-corrected, and B-H corrected p-values are 1.19631E-07, 0.000740394, and 1.45175E-05, respectively. At t30, t60, t90, and 120 the average log fold change are listed as -0.320733333, -0.645233333, -1.147066667, and 2.0331, respectively.
- We will compare the numbers we get between the wild type strain and the other strains studied, organized as a table. Use this sample PowerPoint slide to see how your table should be formatted.
Clustering and GO Term Enrichment with stem
- Prepare your microarray data file for loading into STEM.
- Insert a new worksheet into your Excel workbook, and name it "dswi4_stem".
- Select all of the data from your "dswi4_ANOVA" worksheet and Paste special > paste values into your "dswi4_stem" worksheet.
- Your leftmost column should have the column header "Master_Index". Rename this column to "SPOT". Column B should be named "ID". Rename this column to "Gene Symbol". Delete the column named "Standard_Name".
- Filter the data on the B-H corrected p value to be > 0.05 (that's greater than in this case).
- Once the data has been filtered, select all of the rows (except for your header row) and delete the rows by right-clicking and choosing "Delete Row" from the context menu. Undo the filter. This ensures that we will cluster only the genes with a "significant" change in expression and not the noise.
- Delete all of the data columns EXCEPT for the Average Log Fold change columns for each timepoint (for example, wt_AvgLogFC_t30, etc.).
- Rename the data columns with just the time and units (for example, 30m, 60m etc.).
- Save your work. Then use Save As to save this spreadsheet as Text (Tab-delimited) (*.txt). Click OK to the warnings and close your file.
- Note that you should turn on the file extensions if you have not already done so.
- Now download and extract the STEM software. Click here to go to the STEM web site.
- Click on the download link, register, and download the
stem.zipfile to your Desktop. - Unzip the file. In Seaver 120, you can right click on the file icon and select the menu item 7-zip > Extract Here.
- This will create a folder called
stem. Inside the folder, double-click on thestem.jarto launch the STEM program.
- Click on the download link, register, and download the
- Running STEM
- In section 1 (Expression Data Info) of the the main STEM interface window, click on the Browse... button to navigate to and select your file.
- Click on the radio button No normalization/add 0.
- Check the box next to Spot IDs included in the data file.
- In section 2 (Gene Info) of the main STEM interface window, select Saccharomyces cerevisiae (SGD), from the drop-down menu for Gene Annotation Source. Select No cross references, from the Cross Reference Source drop-down menu. Select No Gene Locations from the Gene Location Source drop-down menu.
- In section 3 (Options) of the main STEM interface window, make sure that the Clustering Method says "STEM Clustering Method" and do not change the defaults for Maximum Number of Model Profiles or Maximum Unit Change in Model Profiles between Time Points.
- In section 4 (Execute) click on the yellow Execute button to run STEM.
- In section 1 (Expression Data Info) of the the main STEM interface window, click on the Browse... button to navigate to and select your file.
- Viewing and Saving STEM Results
- A new window will open called "All STEM Profiles (1)". Each box corresponds to a model expression profile. Colored profiles have a statistically significant number of genes assigned; they are arranged in order from most to least significant p value. Profiles with the same color belong to the same cluster of profiles. The number in each box is simply an ID number for the profile.
- Click on the button that says "Interface Options...". At the bottom of the Interface Options window that appears below where it says "X-axis scale should be:", click on the radio button that says "Based on real time". Then close the Interface Options window.
- Take a screenshot of this window (on a PC, simultaneously press the
AltandPrintScreenbuttons to save the view in the active window to the clipboard) and paste it into a PowerPoint presentation to save your figures.
- Click on each of the SIGNIFICANT profiles (the colored ones) to open a window showing a more detailed plot containing all of the genes in that profile.
- Take a screenshot of each of the individual profile windows and save the images in your PowerPoint presentation.
- At the bottom of each profile window, there are two yellow buttons "Profile Gene Table" and "Profile GO Table". For each of the profiles, click on the "Profile Gene Table" button to see the list of genes belonging to the profile. In the window that appears, click on the "Save Table" button and save the file to your desktop. Make your filename descriptive of the contents, e.g. "wt_profile#_genelist.txt", where you replace the number symbol with the actual profile number.
- Upload these files to OpenWetWare and link to them on your individual journal page. (Note that it will be easier to zip all the files together and upload them as one file).
- For each of the significant profiles, click on the "Profile GO Table" to see the list of Gene Ontology terms belonging to the profile. In the window that appears, click on the "Save Table" button and save the file to your desktop. Make your filename descriptive of the contents, e.g. "wt_profile#_GOlist.txt", where you use "wt", "dGLN3", etc. to indicate the dataset and where you replace the number symbol with the actual profile number. At this point you have saved all of the primary data from the STEM software and it's time to interpret the results!
- Upload these files to OpenWetWare and link to them on your individual journal page. (Note that it will be easier to zip all the files together and upload them as one file).
- A new window will open called "All STEM Profiles (1)". Each box corresponds to a model expression profile. Colored profiles have a statistically significant number of genes assigned; they are arranged in order from most to least significant p value. Profiles with the same color belong to the same cluster of profiles. The number in each box is simply an ID number for the profile.
- Analyzing and Interpreting STEM Results
- Select one of the profiles you saved in the previous step for further intepretation of the data. I suggest that you choose one that has a pattern of up- or down-regulated genes at the cold shock timepoints. Each member of your group should choose a different profile. Answer the following:
- Why did you select this profile? In other words, why was it interesting to you?
- I chose profile 11 because it had the greatest number of genes associated with it (lowest p-value, greatest significance).
- How many genes belong to this profile?
- 231
- How many genes were expected to belong to this profile?
- 48.5
- What is the p value for the enrichment of genes in this profile? Bear in mind that we just finished computing p values to determine whether each individual gene had a significant change in gene expression at each time point. This p value determines whether the number of genes that show this particular expression profile across the time points is significantly more than expected.
- 3.4E-83
- Open the GO list file you saved for this profile in Excel. This list shows all of the Gene Ontology terms that are associated with genes that fit this profile. Select the third row and then choose from the menu Data > Filter > Autofilter. Filter on the "p-value" column to show only GO terms that have a p value of < 0.05.
- 43
- The GO list also has a column called "Corrected p-value". This correction is needed because the software has performed thousands of significance tests. Filter on the "Corrected p-value" column to show only GO terms that have a corrected p value of < 0.05. How many GO terms are associated with this profile with a corrected p value < 0.05?
- 212
- Select 6 Gene Ontology terms from your filtered list (either p < 0.05 or corrected p < 0.05).
- Each member of the group will be reporting on his or her own cluster in your presentation next week. You should take care to choose terms that are the most significant, but that are also not too redundant. For example, "RNA metabolism" and "RNA biosynthesis" are redundant with each other because they mean almost the same thing.
- Note whether the same GO terms are showing up in multiple clusters.
- Look up the definitions for each of the terms at http://geneontology.org. In your final presentation, you will discuss the biological interpretation of these GO terms. In other words, why does the cell react to cold shock by changing the expression of genes associated with these GO terms? Also, what does this have to do with the transcription factor being deleted (for the Δgln3 and Δswi4 groups)?
- To easily look up the definitions, go to http://geneontology.org.
- Copy and paste the GO ID (e.g. GO:0044848) into the search field at center top of the page called "Search GO Data".
- In the results page, click on the button that says "Link to detailed information about <term>, in this case "biological phase"".
- The definition will be on the next results page, e.g. here.
- cortical actin cytoskeleton - “The portion of the actin cytoskeleton, comprising filamentous actin and associated proteins, that lies just beneath the plasma membrane.” [1]
- regulation of cellular component size - “A process that modulates the size of a cellular component.” [2]
- carbohydrate metabolic process - “The chemical reactions and pathways involving carbohydrates, any of a group of organic compounds based of the general formula Cx(H2O)y. Includes the formation of carbohydrate derivatives by the addition of a carbohydrate residue to another molecule.” [3]
- response to stress - “Any process that results in a change in state or activity of a cell or an organism (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a disturbance in organismal or cellular homeostasis, usually, but not necessarily, exogenous (e.g. temperature, humidity, ionizing radiation).” [4]
- reciprocal meiotic recombination - “The cell cycle process in which double strand breaks are formed and repaired through a double Holliday junction intermediate. This results in the equal exchange of genetic material between non-sister chromatids in a pair of homologous chromosomes. These reciprocal recombinant products ensure the proper segregation of homologous chromosomes during meiosis I and create genetic diversity.” [5]
- phosphotransferase activity, alcohol group as acceptor - “Catalysis of the transfer of a phosphorus-containing group from one compound (donor) to an alcohol group (acceptor).” [6]
- Each member of the group will be reporting on his or her own cluster in your presentation next week. You should take care to choose terms that are the most significant, but that are also not too redundant. For example, "RNA metabolism" and "RNA biosynthesis" are redundant with each other because they mean almost the same thing.
- Why did you select this profile? In other words, why was it interesting to you?
- Select one of the profiles you saved in the previous step for further intepretation of the data. I suggest that you choose one that has a pattern of up- or down-regulated genes at the cold shock timepoints. Each member of your group should choose a different profile. Answer the following:
Conclusion
I successfully gained the tools, skills, and knowledge needed to understand and analyze microarray monitoring of gene expression. In the Hebly et al. (2014) study, we found that diurnal temperature cycling of temperature caused budding yeast to adapt stable physiological conditions by genetic expression re-wiring. Ultimately, this re-wiring was centered around the cell cycle, but influenced many other factors such as metabolic rate and carbohydrate utilization. In our analysis of microarray data of dswi4 yeast measured by the Dahlquist Lab, we found some similar genetic expression characteristics. Cell cycle, cellular organization, and metabolism appeared to be important factors under these conditions. Moving forward, we believe future studies should better reflect more natural growth dynamic (such as by using an auxostat) and focus on the aforementioned functions and their relevant gene groups.
Final Group Presentation
Data and Files
Acknowledgments
I would like to thank Matthew Oki, Mia Huddleston, and Matthew Allegretti for their assistance on this project. We met in-class on 11/29/16 and 12/6/16, working together on paper interpretation, data analysis, and presentation. Professor Kam Dahlquist assisted us with concepts during these in-class days as well. Generally, we stayed in contact about individual work on the project over Facebook Messenger from 11/29/16 to 12/12/16, and each team member did their respective analysis for the cold shock data. As a note, I copy-pasted the assignment instructions directly from Assignment Week 15 and edited it for our project. I met with Matt Oki and Mia Huddleston in-person on 11/29/16 to complete the PowerPoint presentation. While I worked with the people noted above, this individual journal entry was completed by me and not copied from another source.
Colin Wikholm 23:45, 12 December 2016 (EST)
References
- Al-Fageeh, M. B., & Smales, C. M. (2006). Control and regulation of the cellular responses to cold shock: the responses in yeast and mammalian systems. Biochemical Journal, 397(Pt 2), 247–259. http://doi.org/10.1042/BJ20060166
- Assignment Week 15
- Hebly, Marit, et al. "Physiological and transcriptional responses of anaerobic chemostat cultures of Saccharomyces cerevisiae subjected to diurnal temperature cycles." Applied and environmental microbiology 80.14 (2014): 4433-4449. doi:10.1128/AEM.00785-14
- Kwong, P. D., Wyatt, R., Robinson, J., Sweet, R. W., Sodroski, J., & Hendrickson, W. A. (1998). Structure of an HIV gp120 envelope glycoprotein in complex with the CD4 receptor and a neutralizing human antibody. Nature, 393(6686), 648-659. DOI: 10.1038/31405
- Müller, F. (2009). Assessing Antibody Neutralization of HIV-1 as an Initial Step in the Search for gp160-based Immunogens (Doctoral dissertation, Universität des Saarlandes Saarbrücken).
- Tran, E. E., Borgnia, M. J., Kuybeda, O., Schauder, D. M., Bartesaghi, A., Frank, G. A., ... & Subramaniam, S. (2012). Structural mechanism of trimeric HIV-1 envelope glycoprotein activation. PLoS Pathog, 8(7), e1002797. http://dx.doi.org/10.1371/journal.ppat.1002797
- Wilen CB, Tilton JC, Doms RW. HIV: Cell Binding and Entry. Cold Spring Harbor Perspectives in Medicine. 2012;2(8):a006866. doi:10.1101/cshperspect.a006866.
- Zhu, J., Dong, C. H., & Zhu, J. K. (2007). Interplay between cold-responsive gene regulation, metabolism and RNA processing during plant cold acclimation. Current opinion in plant biology, 10(3), 290-295. doi:10.1016/S1369-5274(99)80031-9
Important links
Bioinfomatics Lab: Fall 2016
Class Page: BIOL 368-01: Bioinfomatics Laboratory, Fall 2016
| Weekly Assignments | Individual Journal Assignments | Shared Journal Assignments |
|---|---|---|
|
|
|
