Alex A. Cardenas Week 9
From OpenWetWare
Jump to navigationJump to search
HIV Structure Project
- Working with Robert and Zeb.
- V3 loop conformation is the main area of study and comparing these regions with those who developed AIDs and those who did not. We will investigate these different conformations and how they compare with the given numbers such as CD4 T cell count, ratios, etc.
- Rapid progressors sequences will be compared to moderate and non progressors. Subjects of interest are 1, 3, 4, 10, 11, and 15. Moderate progessors of interest 6 and non-progressor 13.
- The following visits for each subject will be studied. We will be comparing pre and post AIDs (in relation to the # of CD4 T cell count). The conformational changes of the V3 loop will be looked at when the subjects have the highest CD4 T cell count and the lowest CD4 T cell count (except for the subjects 6 and 13).
- Subject 1 - visit 1 and 3.
- Subject 3 - visit 1 and 5.
- Subject 4 - visit 1 and 4.
- Subject 10 - visit 1 and 5.
- Subject 11 - visit 1 and 4.
- Subject 15 - visit 1 and 4.
- Subject 6 (moderate progressor) - visit 9.
- Subject 13 (non-progressor)- visit 5.
HIV Structure Project Exercises
- Converting DNA sequences into protein sequences.
- The following amino acid sequences can be found [here].
- This would be done using www.ncbi.nlm.nih.gov/gorf/gorf.html --> and then entering in each of the DNA sequences but the sequence data in BEDROCK already gives us the amino acid sequences.
- Perform a multiple sequence alignment on the protein sequences.
- This was doing through ClustalW (www.ebi.ac.uk/clustalw.). The amino acid sequences were pasted into the ClustalW sequence box and the results were made.
- Subject 1 multiple sequence alignment:

- Subject 3 multiple sequence alignment:

- Subject 4 multiple sequence alignment:

- Subject 10 multiple sequence alignment:

- Subject 11 multiple sequence alignment:

- Subject 15 multiple sequence alignment:

- Subject 6 multiple sequence alignment - ran with last visits of subjects above:
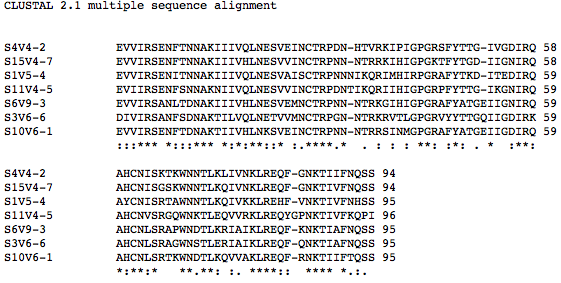
- Subject 13 multiple sequence alignment - ran with all subjects last visits not including subject 6:

- There are fewer differences when looking at the protein sequences when compared to the DNA sequences.
- This can be accounted for because different DNA sequence codons can can still code for the same amino acid.
- Amino acid sequences of all rapid progressors that have AIDs (the last visits where CD4 T Cell count was below 200), were ran against the amino acid sequences of the Moderate progressor 6. The results are shown:








>S11V4-5 EVIIRSENFSNNAKNIIVQLNESVVINCTRPDNTIKQRIIHIGPGRPFYTT-GIKGNIRQ
>S1V5-4 EVVIRSENITNNAKIIIVQLNESVAISCTRPNNNIKQRIMHIRPGRAFYTK-DITEDIRQ
>S4V4-2 EVVIRSENFTNNAKIIIVQLNESVEINCTRPDN-HTVRKIPIGPGRSFYTT-GIVGDIRQ
>S15V4-7 EVVIRSENFTNNAKIIIVHLNESVVINCTRPNN-NTRRKIHIGPGKTFYTG-DIIGNIRQ
>S10V6-1 EVVIRSENFTDNAKTIIVHLNKSVEINCTRPNN-NTRRSINMGPGRAFYATGEIIGDIRQ
>S6V9-3 EVVIRSANLTDNAKIIIVHLNESVEMNCTRPNN-NTRKGIHIGPGRAFYATGEIIGNIRQ
>S3V6-6 DIVIRSANFSDNAKTILVQLNETVVMNCTRPGN-NTRKRVTLGPGRVYYTTGQIIGDIRK
:::*** *:::*** *:*:**::* :.****.* . : : : **: :*: * :**:
>S11V4-5 AHCNVSRGQWNKTLEQVVRKLREQYGPNKTIVFKQPI
>S1V5-4 AYCNISRTAWNNTLKQIVKKLREHF-VNKTIVFNHSS
>S4V4-2 AHCNISKTKWNNTLKLIVNKLREQFG-NKTIIFNQSS
>S15V4-7 AHCNISGSKWNNTLKQIVNKLREQFG-NKTIVFNQSS
>S10V6-1 AHCNLSRTKWNDTLKQVVAKLREQFR-NKTIIFTQSS
>S6V9-3 AHCNLSRAPWNDTLKRIAIKLREQFK-NKTIAFNQSS
>S3V6-6 AHCNLSRAGWNSTLERIAIKLREQFQ-NKTIAFNQSS
*:**:* **.**: :. ****:: **** *.:.
- Then all these were ran against the amino acid sequence of subject 13, a non progressor (used as a control). The multiple sequence alignment is shown below.
>S15V4-7 EVVIRSENFTNNAKIIIVHLNESVVINCTRPNNNTR-RKIHIGPGKTFYTG-DIIGNIRQ
>S1V5-4 EVVIRSENITNNAKIIIVQLNESVAISCTRPNNNIKQRIMHIRPGRAFYTK-DITEDIRQ
>S13V5-1[4] EIVIRSENFTNNAKIIIVQLKESVEINCTRPGNNTR-RSINIGPGRAFYASRGIIGDIRQ
>S10V6-1 EVVIRSENFTDNAKTIIVHLNKSVEINCTRPNNNTR-RSINMGPGRAFYATGEIIGDIRQ
>S4V4-2 EVVIRSENFTNNAKIIIVQLNESVEINCTRPDNHTV-RKIPIGPGRSFYTT-GIVGDIRQ
>S11V4-5 EVIIRSENFSNNAKNIIVQLNESVVINCTRPDNTIKQRIIHIGPGRPFYTT-GIKGNIRQ
>S3V6-6 DIVIRSANFSDNAKTILVQLNETVVMNCTRPGNNTR-KRVTLGPGRVYYTTGQIIGDIRK
:::*** *:::*** *:*:*:::* :.****.* : : : **: :*: * :**:
>S15V4-7 AHCNISGSKWNNTLKQIVNKLREQFG-NKTIVFNQSS
>S1V5-4 AYCNISRTAWNNTLKQIVKKLREHFV-NKTIVFNHSS
>S13V5-1[4] AYCNISKAKWDNTLGQVAAKLREQFR-NATIVFNQSS
>S10V6-1 AHCNLSRTKWNDTLKQVVAKLREQFR-NKTIIFTQSS
>S4V4-2 AHCNISKTKWNNTLKLIVNKLREQFG-NKTIIFNQSS
>S11V4-5 AHCNVSRGQWNKTLEQVVRKLREQYGPNKTIVFKQPI
>S3V6-6 AHCNLSRAGWNSTLERIAIKLREQFQ-NKTIAFNQSS
*:**:* *:.** :. ****:: * ** *.:.
- A multiple sequence alignment was ran using the V3 Loop amino acid sequence for structures 1NAK, 1F58, and 2F58 (Shown Below). There is a slight region that is conserved within the sequence! Although this might be hard to determine between the subjects V3 amino acid sequenes becasue they are much longer than the ones below. We will see how it turns out in the following multiple sequence alignment.
Structure_1NAK ---CKRIHIGPGRAFYTTC----
Structure_1F58 YNKRKRIHIGPGRXFYTTKNIIG
Structure_2F58 -------HIGPGRAFGGG-----
****** *
- Multiple sequence alignment was ran using the sequences from all the subjects that had AIDs and using the sequences from the three structures shown above. There is NO conservation within the loop as seen below --> coming to a conclusion that maybe there are changes in the V3 loop conformation within sequences of those that develop AIDs.
>S15V4-7 EVVIRSENFTNNAKIIIVHLNESVVINCTRPNNNTR-RKIHIGPGKTFYTG-DIIGNIRQ
>S1V5-4 EVVIRSENITNNAKIIIVQLNESVAISCTRPNNNIKQRIMHIRPGRAFYTK-DITEDIRQ
>S4V4-2 EVVIRSENFTNNAKIIIVQLNESVEINCTRPDNHTV-RKIPIGPGRSFYTT-GIVGDIRQ
>S10V6-1 EVVIRSENFTDNAKTIIVHLNKSVEINCTRPNNNTR-RSINMGPGRAFYATGEIIGDIRQ
>S11V4-5 EVIIRSENFSNNAKNIIVQLNESVVINCTRPDNTIKQRIIHIGPGRPFYTT-GIKGNIRQ
>S3V6-6 DIVIRSANFSDNAKTILVQLNETVVMNCTRPGNNTR-KRVTLGPGRVYYTTGQIIGDIRK
Structure_1F58 --------------------------------YNKR-KRIHIGPGRXFYTTKNIIG----
: : : **: :*: *
>S15V4-7 AHCNISGSKWNNTLKQIVNKLREQFG-NKTIVFNQSS
>S1V5-4 AYCNISRTAWNNTLKQIVKKLREHFV-NKTIVFNHSS
>S4V4-2 AHCNISKTKWNNTLKLIVNKLREQFG-NKTIIFNQSS
>S10V6-1 AHCNLSRTKWNDTLKQVVAKLREQFR-NKTIIFTQSS
>S11V4-5 AHCNVSRGQWNKTLEQVVRKLREQYGPNKTIVFKQPI
>S3V6-6 AHCNLSRAGWNSTLERIAIKLREQFQ-NKTIAFNQSS
Structure_1F58 -------------------------------------
>S10V6-1 EVVIRSENFTDNAKTIIVHLNKSVEINCTRPNNNTRRSIN-MGPGRAFYATGEIIGDIRQ
>S3V6-6 DIVIRSANFSDNAKTILVQLNETVVMNCTRPGNNTRKRVT-LGPGRVYYTTGQIIGDIRK
>S4V4-2 EVVIRSENFTNNAKIIIVQLNESVEINCTRPDNHTVRKIP-IGPGRSFYTTG-IVGDIRQ
>S15V4-7 EVVIRSENFTNNAKIIIVHLNESVVINCTRPNNNTRRKIH-IGPGKTFYT-GDIIGNIRQ
>S1V5-4 EVVIRSENITNNAKIIIVQLNESVAISCTRPNNNIKQRIMHIRPGRAFYTK-DITEDIRQ
Structure_2F58 ----------------------------------------HIGPGRAF-------G----
>S11V4-5 EVIIRSENFSNNAKNIIVQLNESVVINCTRPDNTIKQRIIHIGPGRPFYTTG-IKGNIRQ
: **: :
>S10V6-1 AHCNLSRTKWNDTLKQVVAKLREQFR-NKTIIFTQSS >S3V6-6 AHCNLSRAGWNSTLERIAIKLREQFQ-NKTIAFNQSS >S4V4-2 AHCNISKTKWNNTLKLIVNKLREQFG-NKTIIFNQSS >S15V4-7 AHCNISGSKWNNTLKQIVNKLREQFG-NKTIVFNQSS >S1V5-4 AYCNISRTAWNNTLKQIVKKLREHFV-NKTIVFNHSS Structure_2F58 -------G-----------------G----------- >S11V4-5 AHCNVSRGQWNKTLEQVVRKLREQYGPNKTIVFKQPI
>S15V4-7 EVVIRSENFTNNAKIIIVHLNESVVINCTRPNNNTR-RKIHIGPGKTFYTG-DIIGNIRQ
>S1V5-4 EVVIRSENITNNAKIIIVQLNESVAISCTRPNNNIKQRIMHIRPGRAFYTK-DITEDIRQ
>S4V4-2 EVVIRSENFTNNAKIIIVQLNESVEINCTRPDNHTV-RKIPIGPGRSFYTT-GIVGDIRQ
>S10V6-1 EVVIRSENFTDNAKTIIVHLNKSVEINCTRPNNNTR-RSINMGPGRAFYATGEIIGDIRQ
>S3V6-6 DIVIRSANFSDNAKTILVQLNETVVMNCTRPGNNTR-KRVTLGPGRVYYTTGQIIGDIRK
Structure_1NAK ---------------------------CKR---------IHIGPGRAFYTT---------
>S11V4-5 EVIIRSENFSNNAKNIIVQLNESVVINCTRPDNTIKQRIIHIGPGRPFYTT-GIKGNIRQ
*.* : : **: :*:
>S15V4-7 AHCNISGSKWNNTLKQIVNKLREQFG-NKTIVFNQSS
>S1V5-4 AYCNISRTAWNNTLKQIVKKLREHFV-NKTIVFNHSS
>S4V4-2 AHCNISKTKWNNTLKLIVNKLREQFG-NKTIIFNQSS
>S10V6-1 AHCNLSRTKWNDTLKQVVAKLREQFR-NKTIIFTQSS
>S3V6-6 AHCNLSRAGWNSTLERIAIKLREQFQ-NKTIAFNQSS
Structure_1NAK --C----------------------------------
>S11V4-5 AHCNVSRGQWNKTLEQVVRKLREQYGPNKTIVFKQPI
- As seen from the multiple sequence alignments above, there are conserved regions of the V3 loop. However, these amino acid sequences show that there is not a major conserved region in the seqeunces that have AIDs when compared to the sequences that do not have AIDs (subject 6 and 13).
- Which of the procedures from Chapter 6 that you ran on the entire gp120 sequence are applicable to the V3 fragment you are working with now? The procedures from Chapter 6 that are applicable to the V3 fragment that we are working with now are: doing primary structure analysis and finding domains in the protein.
- How are they applicable? The primary strucutre analysis can be helpful because it can help us determine how the protein will fold. This will be helpful because it allows us to determine/see the hydrophobic regions, the coiled regions, and the hydrophilic regions that are within the protein. The finding domains procedure can help us in looking for a specific domain/sequence that will help is in determining the differeneces and similarities within the different V3 loop conformations. We can run multiple sequence alignments on this and determine how the different domains are similar.
- Chapter 11 contains procedures to use for working with protein 3D structures. Find the section on "Predicting the Secondary Structure of a Protein Sequence" and perform this on both the entire gp120 sequence and on the V3 fragment that we are now working with. You will compare the predictions with the actual structures.
- Amino acid sequence of gp120 found below. Zeb found this because the pages in the book did not work.
- Amino acid sequence of gp120 found below. Zeb found this because the pages in the book did not work.
- Download the structure files for the papers we read in journal club from the NCBI Structure Database.
- Using StarBiochem to work with gp120 peptide and the ternary complex structures.
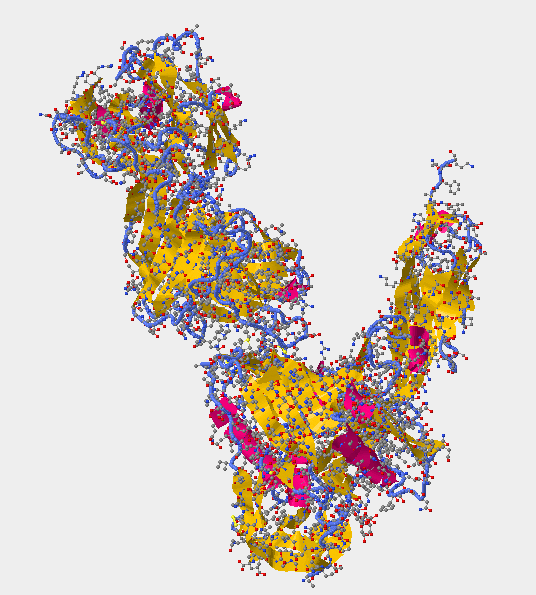
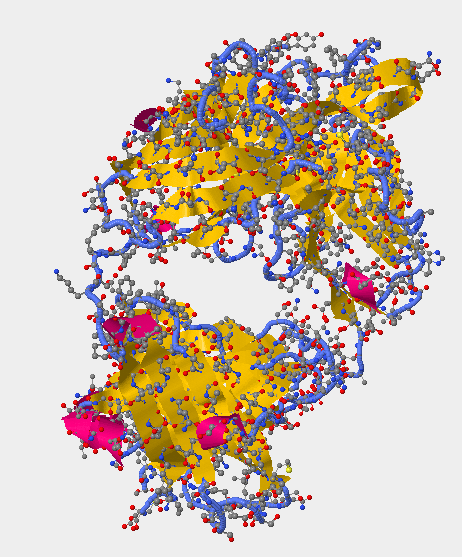
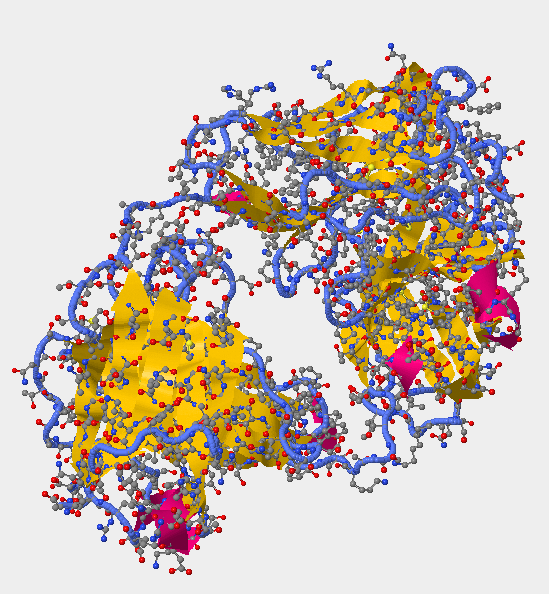
- Locate all the secondary structure elements (found below. purple=helices; yellow=sheets; blue=coils. Do these match the predictions you made above? Yes for all of the helices --> they match. As for the sheets and coils, some of them match while others do not.
- Secondary Structure 1GC1 -
- Secondary Structure 1F58 -
- Secondary Structure 2F58 -
- Secondary Structure 1NAK -
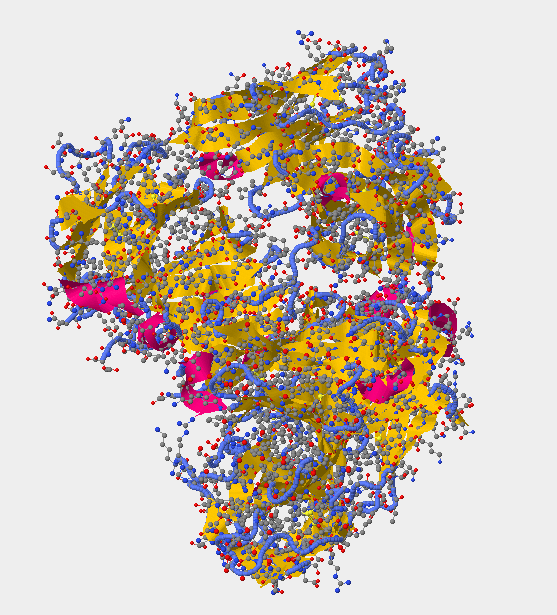
- Secondary Structure 1GC1 -
- Locate the V3 region and figure out which sequences from your alignment are present in the structures and which sequences are absent.
- V3 region for secondary structure 1GC1 is not present --> has the whole gp120 excluding V3 region. Region 300G-328G is missing! In between the coil (blue) and sheet (yellow) in the following picture is where the V3 region should be.
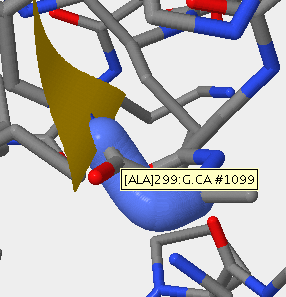
- V3 region for secondary structure 1F58 is found 313P-325P.
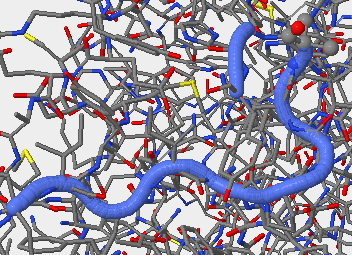
- V3 region for secondary structure 2F58 is found 315P-324P.
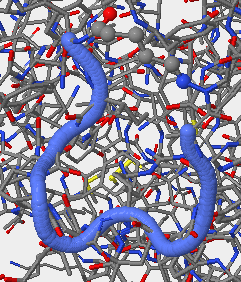
- V3 region for secondary structure 1NAK is found 312P-323P.
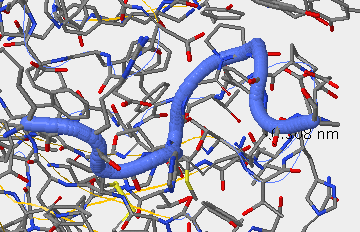
- V3 region for secondary structure 1GC1 is not present --> has the whole gp120 excluding V3 region. Region 300G-328G is missing! In between the coil (blue) and sheet (yellow) in the following picture is where the V3 region should be.
- Locate all the secondary structure elements (found below. purple=helices; yellow=sheets; blue=coils. Do these match the predictions you made above? Yes for all of the helices --> they match. As for the sheets and coils, some of them match while others do not.













Powerpoint
- My part of the powerpoint can be found here.
- Updated powerpoint including Zeb's slides can be found here: Updated ppt with work from Alex and Zeb.
- Slides from Svicher article
- Final powerpoint
Links
- Alex A. Cardenas
- Week 9 Assignment
- Alex A. Cardenas Week 2
- Alex A. Cardenas Week 3
- Alex A. Cardenas Week 4
- Alex A. Cardenas Week 5
- Alex A. Cardenas Week 6
- Alex A. Cardenas Week 7
- Alex A. Cardenas Week 8
- Alex A. Cardenas Week 9
- Alex A. Cardenas Week 10
- Alex A. Cardenas Week 11
- Alex A. Cardenas Week 12
- Alex A. Cardenas Week 13
- Alex A. Cardenas Week 14
- Class Journal Week 1
- Class Journal Week 2
- Class Journal Week 3
- Class Journal Week 5
- Class Journal Week 6
- Class Journal Week 7
- Class Journal Week 8
- Class Journal Week 9
- Class Journal Week 10
- Class Journal Week 11
- Class Journal Week 12
- Class Journal Week 13
- Class Journal Week 14
