BIOL478/S16:Microarray Data Analysis
Laboratory 10: Microarray Data Analysis Wednesday, April 13, Wednesday, April 20, Monday, April 25, and Wednesday, April 27
Before We Begin
Viewing File Extensions
- The Windows 7 operating systems defaults to hiding file extensions. To turn them back on, do the following:
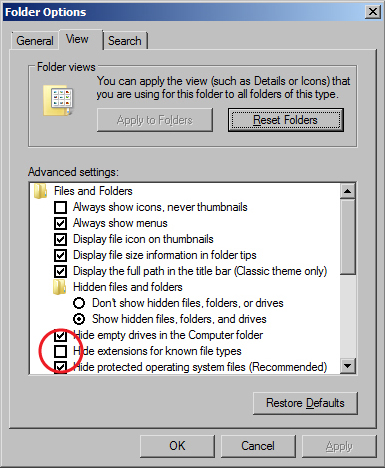
Folder Options window - Go to the Start menu and select "Control Panel".
- In the window that appears, search for "Folder Options" in the search field in the upper right hand corner.
- Click on "Folder Options" in the main window.
- When the Folder Options window appears, click on the View tab.
- Uncheck the box for "Hide extensions for known file types".
- Click the OK button.

Set Your Browser to Prompt You for the Location to Save your Downloaded Files
- In Mozilla Firefox, open the Options window.
- Select the radio button that says "Always ask me where to save files".
- You could also change the default "Save files to" location to your Desktop, so that will be the first choice when it prompts you where to save the file. (You will have to temporarily deselect the radio button to do this and then reselect it when you are done.
- Click OK to save your changes.
- In Google Chrome, open the Settings window.
- Click on the link at the bottom of the page that says "Advanced Settings".
- Check the box that says "Ask where to save each file before downloading".
- You could also change the default Download location to your Desktop, so that will be the first choice when it prompts you where to save the file.
- Your settings are automatically saved.
Background
This is a list of steps required to analyze DNA microarray data.
- Quantitate the fluorescence signal in each spot
- Calculate the ratio of red/green fluorescence
- Log2 transform the ratios
- Steps 1-3 are performed by the GenePix Pro software
- Normalize the ratios on each microarray slide
- Normalize the ratios for a set of slides in an experiment
- Steps 4-5 are performed by using a script written in the R statistical programming language
- Perform statistical analysis on the ratios
- Compare individual genes with known data
- Steps 6-7 are performed in Microsoft Excel
- Pattern finding algorithms (clustering)
- We will use software called STEM for clustering
- Mapping onto biological pathways
- We will use software called GenMAPP for mapping onto biological pathways
- Identifying regulatory transcription factors responsible for observed changes in gene expression
GenePix Pro Protocol (Steps 1-3)
- Follow this link to download the raw image files. Put them on the Desktop.
- Right-click on the zipped file and select the menu item 7-zip > Extract here. This will extract the raw image files so that we can open them in GenePix Pro.
Gridding and Generating Intensity Data
- Launch GenPix Pro 6.1 (select Analysis Only)
- On the right hand side of the screen, select the File icon
- Select File > Open Images
- Navigate to the folder containing your .tif images
- Hold down the Control key while clicking to select both the 532 and 635 wavelength files
- Click on the Open button
- Use the brightness and contrast sliders on the upper left hand side to adjust your image to see all of the spots
- You can use the magnifying glass icon to zoom in on an area of the image, and the magnifying glass return icon to go back to the whole chip image
- Zoom in so that you can see the entire top block of grids on your screen
- On the right hand side of the screen, select the File icon
- Select Load Array List
- Select the file Ontario_Y6.4Kv7.GAL
- To download this file, right-click on the link and select "Save link as..." from the context menu that appears.
- Click the Open button
- Using the icon that has an arrow and a square, drag the grids so that they are approximately aligned with the top block of spots
- Click on the icon that looks like a compass, or a circle with cross-hairs, and select Find Array, Find All blocks, Align Features
- Alternately, you can do this in three steps by:
- Click on the icon that looks like a compass, or a circle with cross-hairs, and select Find Array
- Click on the icon again, and select Find All Blocks
- Click on the icon again, and select Align Features in All Blocks
- Alternately, you can do this in three steps by:
- Click on the icon that looks like a compass, or a circle with cross-hairs, and select Find Array, Find All blocks, Align Features
- On the right hand side of the screen, select the icon that looks like a table of data (it says B, C, R at the top of it)
- Click on the File icon on the right hand side and select, Save Results As, and save your results as type "GenePix Pro Files (*.gpr)". Save a JPEG image containing all analyzed features.
Generating an Array Quality Report
- Launch GenePix Pro 6.1 (select Analysis Only)
- On the right hand side of the screen, select the File icon
- File > Open Results
- Select the desired file
- Select Report tab at the top of the screen
- On the left side of the screen, under Navigate, select the back arrow or home icon
- Select Array Quality Control
- Adjust Vital Statistic Thresholds values to:
Quality Control Limits Median signal to background > 2.5 Mean of Median background < 500 Median Signal to Noise > 4 Median % >B + 1 StdDev > 90 Feature variation < 0.5 Background Variation < 1.2 Features with Saturated pixels < 3.3% Not Found < 18% Bad Features < 7%
- Select Start
- Select Show Printable Version
- File > Print
- Under Select Printer > Select Adobe PDF
- Select Print
- Save on the Desktop
- Name the file: ChipBarcode#_yyyymmdd
- The PDF file will either open on its own or you need to open it from the file you saved it to
Looking at the raw data
- We will look at the raw data for two genes of interest, ASH1 (which should have been deleted in this strain), and NSR1, which is a gene known to be induced by cold shock.
- Open your results file from the first section of this protocol in Microsoft Excel
- To find the data for NSR1, first go to the NSR1 page at the Saccharomyces Gene Database to learn what the systematic name (ID) for NSR1 is.
- Then search for this ID in your Excel spreadsheet
- This will tell you the block, row, and column where the NSR1 spot occurs and you can look for it in GenePix Pro.
- Repeat with ASH1 (ASH1 page at the Saccharomyces Gene Database)
- We are expecting that NSR1 should be expressed and that ASH1 should not because it has been deleted from the yeast genome. Is this the case?
Within- and Between-chip Normalization (Steps 4-5)
Software Version Information
The following protocol was developed to normalize GCAT and Ontario DNA microarray chip data from the Dahlquist lab using the R Statistical Software and the limma package (part of the Bioconductor Project).
- The normalization procedure has been verified to work with version 3.1.0 of R released in April 2014 (link to download site) and and version 3.20.1 of the limma package ( direct link to download zipped file) on the Windows 7 platform.
- Note that using other versions of R or the limma package might give different results.
- Note also that using the 32-bit versus the 64-bit versions of R 3.1.0 will give different results for the normalization out in the 10-13 or 10-14 decimal place. The Dahlquist Lab is standardizing on using the 64-bit version of R.
Running the Normalization Script
- Create a folder on your Desktop to store your files for the microarray analysis procedure.
- Download the zipped file that contains the
.gprfiles and save it to this folder (or move it if it saved in a different folder).- Unzip this file using 7-zip. Right-click on the file and select the menu item, "7-zip > Extract Here".
- Download the following files by right-clicking on the link and choosing the menu item "Save Link As..."
- Download the GCAT_Targets_wt-dASH1_20160419.csv file and Ontario_Targets_wt-dASH1_20160419.csv files and save them to this folder (or move them if they saved to a different folder).
- Download the BIOL478_Spring2016_bigFatNormalization2.R script and save (or move) it to this folder.
- Download the generatePlots1.R script and save (or move) it to this folder.
- Launch R x64 3.1.0 (make sure you are using the 64-bit version).
- Change the directory to the folder containing the targets file and the GPR files for the chips by selecting the menu item File > Change dir... and clicking on the appropriate directory. You will need to click on the + sign to drill down to the right directory. Once you have selected it, click OK.
- In R, select the menu item File > Source R code..., and select the bigFatNormalization2.R script.
- Wait while R processes your files.
- When the processing has finished, you will find three files called GCAT_and_Ontario_Unnormalized.csv, GCAT_and_Ontario_Within_Array_Normalization.csv, GCAT_and_Ontario_Between_Array_Normalization.csv. The latter file is the one that you will need going forward.
- Save these files to a flash drive (and/or other storage).
Visualizing the Normalized Data
- Immediately after running the normalization script, select the menu item File > Source R code..., and select the generatePlots1.R script.
- Wait while R processes your files. You will see the individual plots being created in a new window. R will save them automatically to the same folder that contains the data and scripts.
- The box plots for each strain (comparison of the before, after within- and after between-chip normalization in the same file) are saved under the name of the strain, e.g., dASH1.jpg.
- The MA plots are saved under a name for the individual chip, e.g., dASH1_LogFC_t15-3.jpg, and show the plots both before and after normalization.
- Wait while R processes your files. You will see the individual plots being created in a new window. R will save them automatically to the same folder that contains the data and scripts.
- Zip the files of the plots together and save to a flash drive (and/or other storage).
Statistical Analysis (Step 6)
Preparing the Spreadsheet
- For the statistical analysis, we will begin with the file "GCAT_and_Ontario_Between_Array_Normalization.csv" that you generated in the previous step.
- Open this file in Excel and Save As an Excel Workbook
*.xlsx. Add your initials and the date (yyyymmdd) to the filename as well. - Rename the worksheet with the data "Compiled_Normalized_Data".
- Type the header "ID" in cell A1.
- Insert a new column after column A and name it "Standard Name". Column B will contain the common names for the genes on the microarray.
- Copy the entire column of IDs from Column A.
- Paste the names into the "Value" field of the ORF List <-> Gene List tool in YEASTRACT. Then, click on the "Transform" button.
- Select all of the names in the "Gene Name" column of the resulting table.
- Copy and paste these names into column B of the
*.xlsxfile. Save your work.
- Insert a new column on the very left and name it "MasterIndex". We will create a numerical index of genes so that we can always sort them back into the same order.
- Type a "1" in cell A2 and a "2" in cell A3.
- Select both cells. Hover your mouse over the bottom-right corner of the selection until it makes a thin black + sign. Double-click on the + sign to fill the entire column with a series of numbers from 1 to 6189 (the number of genes on the microarray).
- Insert a new worksheet and call it "Rounded_Normalized_Data". We are going to round the normalization results to four decimal places because of slight variations seen in different runs of the normalization script.
- Copy the first three columns of the "Compiled_Normalized_Data" sheet and paste it into the first three columns of the "Rounded_Normalized_Data" sheet.
- Copy the first row of the "Compiled_Normalized_Data" sheet and paste it into the first row of the "Rounded_Normalized_Data" sheet.
- In cell D2, type the equation
=ROUND(Compiled_Normalized_Data!D2,4). - Copy and paste this equation in the rest of the cells of row 2.
- Select all of the cells of row 2 and hover your mouse over the bottom right corner of the selection. When the cursor changes to a thin black "plus" sign, double-click on it to paste the equation to all the rows in the worksheet. Save your work.
- Insert a new worksheet and call it "Master_Sheet".
- Go back to the "Rounded_Normalized_Data" sheet and Select All and Copy.
- Click on cell A1 of the "Master_Sheet" worksheet. Select Paste special > Paste values to paste the values, but not the formulas from the previous sheet. Save your work.
- There will be some #VALUE! errors in cells where there was missing data for genes that existed on the Ontario chips, but not the GCAT chips.
- Select the menu item Find/Replace and Find all cells with "#VALUE!" and replace them with a single space character. Record how many replacements were made. Save your work.
- This will be the starting point for our statistical analysis below.
Modified t test for each timepoint
We will perform a modified t test to determine if any genes had a gene expression change that was significantly different than zero at each timepoint. Note that we can only perform the analysis on the wild type strain because we do not have replicates for the Δash1 strain.
- Insert a new worksheet into your Excel workbook and name it "wt_ttest".
- Go back to the "Master_Sheet" worksheet for your strain. Copy the first three columns containing the "MasterIndex", "ID", and "Standard Name" from the "Master_Sheet" worksheet for your strain and paste it into your new worksheet. Copy the columns containing the data for your strain and paste it into your new worksheet.
- Go to the empty columns to the right on your worksheet. Create new column headings in the top cells to label the average log fold changes that you will compute. Name them with the pattern wt_<AvgLogFC>_<tx> where you use the appropriate text within the <> and where x is the time. For example, "wt_AvgLogFC_t15".
- Compute the average log fold change for the replicates for each timepoint by typing the equation:
=AVERAGE(range of cells in the row for that timepoint)
into the second cell below the column heading. For example, your equation might read
=AVERAGE(C2:F2)
Copy this equation and paste it into the rest of the column.
- Create the equation for the rest of the timepoints and paste it into their respective columns. Note that you can save yourself some time by completing the first equation for all of the averages and then copy and paste all the columns at once.
- Go to the empty columns to the right on your worksheet. Create new column headings in the top cells to label the T statistic that you will compute. Name them with the pattern <wt>_<Tstat>_<tx> where you use the appropriate text within the <> and where x is the time. For example, "wt_Tstat_t15". You will now compute a T statistic that tells you whether the normalized average log fold change is significantly different than 0 (no change in expression). Enter the equation into the second cell below the column heading:
=AVERAGE(range of cells)/(STDEV(range of cells)/SQRT(number of replicates))
For example, your equation might read:
=AVERAGE(C2:F2)/(STDEV(C2:F2)/SQRT(4))
(NOTE: in this case the number of replicates is 4. Be careful that you are using the correct number of parentheses.) Copy the equation and paste it into all rows in that column. Create the equation for the rest of the timepoints and paste it into their respective columns. Note that you can save yourself some time by completing the first equation for all of the T statistics and then copy and paste all the columns at once.
- Go to the empty columns to the right on your worksheet. Create new column headings in the top cells to label the P value that you will compute. Name them with the pattern <wt>_<Pval>_<tx> where you use the appropriate text within the <> and where x is the time. For example, "wt_Pval_t15". In the cell below the label, enter the equation:
=TDIST(ABS(cell containing T statistic),degrees of freedom,2)
For example, your equation might read:
=TDIST(ABS(AE2),3,2)
The number of degrees of freedom is the number of replicates minus one. Copy the equation and paste it into all rows in that column.
- Now we will perform adjustments to the p value to correct for the multiple testing problem.
Bonferroni Correction
- Now we will perform adjustments to the p value to correct for the multiple testing problem. Label the columns to the right with the label, wt_Bonferroni-Pval_tx (do this twice in a row).
- Type the equation
=<(STRAIN)_Pval_tx>*6189, Upon completion of this single computation, use the trick to copy the formula throughout the column. - Replace any corrected p value that is greater than 1 by the number 1 by typing the following formula into the first cell below the second wt_Bonferroni-Pval_tx header:
=IF([cell with p value]>1,1,[cell with p value]). Use the trick to copy the formula throughout the column.
Benjamini & Hochberg Correction
- Insert a new worksheet named "wt_ttest_B-H". You will need to perform the procedure below for the p values for each timepoint. Do them individually one at a time to avoid confusion.
- Copy and paste the "MasterIndex", "ID", and "Standard Name" columns from your previous worksheet into the first two columns of the new worksheet.
- For the following, use Paste special > Paste values. Copy your unadjusted p values from the first timepoint from your ttest worksheet and paste it into Column D.
- Select all of columns A, B, C, and D. Sort by ascending values on Column D. Click the sort button from A to Z on the toolbar, in the window that appears, sort by column D, smallest to largest.
- Type the header "Rank" in cell E1. We will create a series of numbers in ascending order from 1 to 6189 in this column. This is the p value rank, smallest to largest. Type "1" into cell E2 and "2" into cell E3. Select both cells E2 and E3. Double-click on the plus sign on the lower right-hand corner of your selection to fill the column with a series of numbers from 1 to 6189.
- Now you can calculate the Benjamini and Hochberg p value correction. Type (STRAIN)_B-H_Pval_tx in cell F1. Type the following formula in cell F2:
=(D2*6189)/E2and press enter. Copy that equation to the entire column. - Type "STRAIN_B-H_Pval_tx" into cell G1.
- Type the following formula into cell G2:
=IF(F2>1,1,F2)and press enter. Copy that equation to the entire column. - Select columns A through G. Now sort them by your MasterIndex in Column A in ascending order.
- Copy column G and use Paste special > Paste values to paste it into the next column on the right of your ttest sheet.
- Save your file to your flash drive (and/or other storage). Give Dr. Dahlquist a copy of the file.
Sanity Check: Number of genes significantly changed
- We will also perform the "sanity check" as follows:
- Go to your wt_ttest worksheet.
- Select row 1 (the row with your column headers) and select the menu item Data > Filter > Autofilter (The funnel icon on the Data tab). Little drop-down arrows should appear at the top of each column. This will enable us to filter the data according to criteria we set.
- Click on the drop-down arrow for the unadjusted p value for t60. Set a criterion that will filter your data so that the p value has to be less than 0.05.
- How many genes have p < 0.05? and what is the percentage (out of 6189)?
- How many genes have p < 0.01? and what is the percentage (out of 6189)?
- How many genes have p < 0.001? and what is the percentage (out of 6189)?
- How many genes have p < 0.0001? and what is the percentage (out of 6189)?
- Determine how many genes have a p value < 0.05 at each of the other timepoints (t15, t30, t90, t120).
- When we use a p value cut-off of p < 0.05, what we are saying is that you would have seen a gene expression change that deviates this far from zero by chance less than 5% of the time.
- We have just performed 6189 hypothesis tests. Another way to state what we are seeing with p < 0.05 is that we would expect to see this a gene expression change for at least one of the timepoints by chance in about 5% of our tests, or 309 times. Since we have more than 309 genes that pass this cut off, we know that some genes are significantly changed. However, we don't know which ones. To apply a more stringent criterion to our p values, we performed the Bonferroni and Benjamini and Hochberg corrections to these unadjusted p values. The Bonferroni correction is very stringent. The Benjamini-Hochberg correction is less stringent. To see this relationship, filter your data to determine the following:
- How many genes are p < 0.05 for the Bonferroni-corrected p value at each timepoint? and what is the percentage (out of 6189)?
- How many genes are p < 0.05 for the Benjamini and Hochberg-corrected p value at each timepoint? and what is the percentage (out of 6189)?
- In summary, the p value cut-off should not be thought of as some magical number at which data becomes "significant". Instead, it is a moveable confidence level. If we want to be very confident of our data, use a small p value cut-off. If we are OK with being less confident about a gene expression change and want to include more genes in our analysis, we can use a larger p value cut-off.
- There is one last thing to do: keeping the "Pval" filter at p < 0.05, How many have an average log fold change of > 0.25 and p < 0.05 at each timepoint? How many have an average log fold change of < -0.25 and p < 0.05 at each timepoint? (These log fold change cut-offs represent about a 20% fold change in expression.)
- Use this sample PowerPoint slide to see how your table should be formatted.
Comparing results with known data
- The expression of the gene NSR1 (ID: YGR159C)is known to be induced by cold shock. Find NSR1 in your dataset. What is its Log fold change at each of the timepoints in the experiment and what is its unadjusted, Bonferroni-corrected, and B-H-corrected p values? What is its average Log fold change at each of the timepoints in the experiment?
Clustering and GO Term Enrichment with stem (steps 7-8)
- Prepare your microarray data file for loading into STEM.
- Insert a new worksheet into your Excel workbook, and name it "wt_stem".
- Select all of the data from your "wt_ttest" worksheet and Paste special > paste values into your "wt_stem" worksheet.
- In addition, paste in the Δash1 data from the "Master_Sheet" worksheet, immediately to the right of the wt data.
- Your leftmost column should have the column header "MasterIndex". Rename this column to "SPOT". Column B should be named "ID". Rename this column to "Gene Symbol". Delete the column named "StandardName".
- You are now going to filter the data in such a way so that we can remove the "least significant" genes from the clustering analysis (if we keep them, the program will just be clustering noise.) Filter the data on the B-H corrected p value for t15 to be > 0.05 (that's greater than in this case). Then filter the B-H corrected p value for t30, t60, t90, and t120 to be > 0.05, without removing the filter from t15. This will select all genes that did not have a significant change in expression any any timepoint in the experiment.
- Once the data has been filtered, select all of the rows (except for your header row) and delete the rows by right-clicking and choosing "Delete Row" from the context menu. Undo the filter. This ensures that we will cluster only the genes with a "significant" change in expression and not the noise.
- Now copy the columns named "SPOT" and "ID" to a new worksheet called "dASH1_stem".
- Copy all of the Δash1 data from the "wt_stem" worksheet over to the "dAHS1_stem" worksheet.
- Back in the "wt_stem" worksheet, delete all of the data columns EXCEPT for the Average Log Fold change columns for each timepoint (for example, wt_AvgLogFC_t15, etc.).
- Rename the data columns with just the time and units (for example, 15m, 30m, etc.).
- In the "dASH1_stem" worksheet, rename the data columns with just the time and units (for example, 15m, 30m, etc.).
- Save your work. Then use Save As to save this the wt_stem worksheet as Text (Tab-delimited) (*.txt). Include "wt" and "stem" in the filename to distinguish it from your other file. Click OK to the warnings. Use Save As to save the dASH1_stem worksheet as Text (Tab-delimited) (*.txt). Include "dASH1" and "stem" in the filename to distinguish it from your other files. Click OK to the warnings and close your file.
- Note that we are going to run stem twice, once on the wt data and once on the Δash1 data.
- Now download and extract the STEM software. Click here to go to the STEM web site.
- Click on the download link, register, and download the
stem.zipfile to your Desktop. - Unzip the file. You can right click on the file icon and select the menu item 7-zip > Extract Here.
- This will create a folder called
stem. Inside the folder, double-click on thestem.jarto launch the STEM program.
- Click on the download link, register, and download the
- Running STEM
- In section 1 (Expression Data Info) of the the main STEM interface window, click on the Browse... button to navigate to and select your file. We will do the wild type data first and then come back and do the Δash1 data later.
- Click on the radio button No normalization/add 0.
- Check the box next to Spot IDs included in the data file.
- In section 2 (Gene Info) of the main STEM interface window, select Saccharomyces cerevisiae (SGD), from the drop-down menu for Gene Annotation Source. Select No cross references, from the Cross Reference Source drop-down menu. Select No Gene Locations from the Gene Location Source drop-down menu.
- In section 3 (Options) of the main STEM interface window, make sure that the Clustering Method says "STEM Clustering Method" and do not change the defaults for Maximum Number of Model Profiles or Maximum Unit Change in Model Profiles between Time Points.
- In section 4 (Execute) click on the yellow Execute button to run STEM.
- In section 1 (Expression Data Info) of the the main STEM interface window, click on the Browse... button to navigate to and select your file. We will do the wild type data first and then come back and do the Δash1 data later.
- Viewing and Saving STEM Results
- A new window will open called "All STEM Profiles (1)". Each box corresponds to a model expression profile. Colored profiles have a statistically significant number of genes assigned; they are arranged in order from most to least significant p value. Profiles with the same color belong to the same cluster of profiles. The number in each box is simply an ID number for the profile.
- Click on the button that says "Interface Options...". At the bottom of the Interface Options window that appears below where it says "X-axis scale should be:", click on the radio button that says "Based on real time". Then close the Interface Options window.
- Take a screenshot of this window (on a PC, simultaneously press the
AltandPrintScreenbuttons to save the view in the active window to the clipboard) and paste it into a PowerPoint presentation to save your figures.
- Click on each of the SIGNIFICANT profiles (the colored ones) to open a window showing a more detailed plot containing all of the genes in that profile.
- Take a screenshot of each of the individual profile windows and save the images in your PowerPoint presentation.
- At the bottom of each profile window, there are two yellow buttons "Profile Gene Table" and "Profile GO Table". For each of the profiles, click on the "Profile Gene Table" button to see the list of genes belonging to the profile. In the window that appears, click on the "Save Table" button and save the file to your desktop. Make your filename descriptive of the contents, e.g. "wt_profile#_genelist.txt", where you replace the number symbol with the actual profile number.
- Save these files to your flash drive (or other storage). (It will be easier to zip all the files together and store them as one file).
- For each of the significant profiles, click on the "Profile GO Table" to see the list of Gene Ontology terms belonging to the profile. In the window that appears, click on the "Save Table" button and save the file to your desktop. Make your filename descriptive of the contents, e.g. "wt_profile#_GOlist.txt", where you use "wt", "dGLN3", etc. to indicate the dataset and where you replace the number symbol with the actual profile number. At this point you have saved all of the primary data from the STEM software and it's time to interpret the results!
- Save these files to your flash drive (or other storage). (It will be easier to zip all the files together and store them as one file).
- Repeat this for the Δash1 data.
- A new window will open called "All STEM Profiles (1)". Each box corresponds to a model expression profile. Colored profiles have a statistically significant number of genes assigned; they are arranged in order from most to least significant p value. Profiles with the same color belong to the same cluster of profiles. The number in each box is simply an ID number for the profile.
- Analyzing and Interpreting STEM Results
- Which profiles were shared by the two strains and which ones were different?
- Each person in the class will select one profile for further analysis; either profile #45 or profile #22, which were the same for the two strains. Answer the following for both the wild type and Δash1 data:
- Why did you select this profile? In other words, why was it interesting to you?
- How many genes belong to this profile for each of the strains?
- How many genes were expected to belong to this profile for each of the strains?
- What is the p value for the enrichment of genes in this profile for each of the strains? Bear in mind that we just finished computing p values to determine whether each individual gene had a significant change in gene expression at each time point. This p value determines whether the number of genes that show this particular expression profile across the time points is significantly more than expected.
- Open the GO list file you saved for this profile in Excel. This list shows all of the Gene Ontology terms that are associated with genes that fit this profile. Select the third row and then choose from the menu Data > Filter > Autofilter. Filter on the "p-value" column to show only GO terms that have a p value of < 0.05. How many GO terms are associated with this profile at p < 0.05? The GO list also has a column called "Corrected p-value". This correction is needed because the software has performed thousands of significance tests. Filter on the "Corrected p-value" column to show only GO terms that have a corrected p value of < 0.05. How many GO terms are associated with this profile with a corrected p value < 0.05 for each of the strains?
- Select 10 Gene Ontology terms from your filtered list (either p < 0.05 or corrected p < 0.05).
- You can either:
- Choose the same 10 terms that are in common between strains (if you can find any).
- Choose 10 terms that are different between the strains (5 or so from each).
- Choose some that are the same (if you can find any) and some that are different.
- Look up the definitions for each of the terms at http://geneontology.org. For your final lab report, you will discuss the biological interpretation of these GO terms. In other words, why does the cell react to cold shock by changing the expression of genes associated with these GO terms? Also, what does this have to do with ASH1 being deleted?
- To easily look up the definitions, go to http://geneontology.org.
- Copy and paste the GO ID (e.g. GO:0044848) into the search field at the upper left of the page called "Search GO Data".
- In the results page, click on the button that says "Link to detailed information about <term>, in this case "biological phase"".
- The definition will be on the next results page, e.g. here.
- You can either:
Map onto Biological Pathways using GenMAPP (Step 9)
Preparing the input file for GenMAPP
- You will go back to the Excel spreadsheet with your statistical calculations from step 6. We will now format this file for use with GenMAPP.
- Create a new worksheet called "forGenMAPP".
- Like you did when preparing the data for stem, select all of the data from your "wt_ttest" worksheet and Paste special > paste values into your "wt_stem" worksheet.
- In addition, paste in the Δash1 data from the "Master_Sheet" worksheet, immediately to the right of the wt data.
- Currently, the "MasterIndex" column is the first column in the worksheet. We need the "ID" column to be the first column. Select Column B and Cut. Right-click on Cell A1 and select "Insert cut cells". This will reverse the position of the columns.
- Insert a new empty column in Column B. Type "SystemCode" in the first cell and "D" in the second cell of this column. Use our trick to fill this entire column with "D".
- Make sure to save this work as your .xlsx file. Now save this worksheet as a tab-delimited text file for use with GenMAPP in the next section.
Downloading the GenMAPP Gene Database for yeast
Each time you launch GenMAPP, you need to make sure that the correct Gene Database (.gdb) is loaded.
- Look in the lower left-hand corner of the window to see which Gene Database has been selected.
- If you need to change the Gene Database, select Data > Choose Gene Database. Navigate to the directory C:\GenMAPP 2 Data\Gene Databases and choose the correct one for your species.
- For the exercise today, if the yeast Gene Database is not present on your computer, you will need to download it. Click this link to download the yeast Gene Database.
- Unzip the file and save it, Sc-Std_20060526.gdb, to the folder C:\GenMAPP 2 Data\Gene Databases.
GenMAPP Expression Dataset Manager Procedure
- Launch the GenMAPP Program. Check to make sure the correct Gene Database is loaded.
- Select the Data menu from the main Drafting Board window and choose Expression Dataset Manager from the drop-down list. The Expression Dataset Manager window will open.
- Select New Dataset from the Expression Datasets menu. Select the tab-delimited text file that you formatted for GenMAPP (.txt) in the procedure above from the file dialog box that appears.
- The Data Type Specification window will appear. GenMAPP is expecting that you are providing numerical data. If any of your columns has text (character) data, check the box next to the field (column) name.
- The column StandardName has text data in it, but none of the rest do.
- Allow the Expression Dataset Manager to convert your data.
- This may take a few minutes depending on the size of the dataset and the computer’s memory and processor speed. When the process is complete, the converted dataset will be active in the Expression Dataset Manager window and the file will be saved in the same folder the raw data file was in, named the same except with a .gex extension; for example, MyExperiment.gex.
- A message may appear saying that the Expression Dataset Manager could not convert one or more lines of data. Lines that generate an error during the conversion of a raw data file are not added to the Expression Dataset. Instead, an exception file is created. The exception file is given the same name as your raw data file with .EX before the extension (e.g., MyExperiment.EX.txt). The exception file will contain all of your raw data, with the addition of a column named ~Error~. This column contains either error messages or, if the program finds no errors, a single space character.
- Record the number of errors in your lab notebook.
- Customize the new Expression Dataset by creating new Color Sets which contain the instructions to GenMAPP for displaying data on MAPPs.
- Color Sets contain the instructions to GenMAPP for displaying data from an Expression Dataset on MAPPs. Create a Color Set by filling in the following different fields in the Color Set area of the Expression Dataset Manager: a name for the Color Set, the gene value, and the criteria that determine how a gene object is colored on the MAPP. Enter a name in the Color Set Name field that is 20 characters or fewer. You will have one Color Set per strain per time point.
- The Gene Value is the data displayed next to the gene box on a MAPP. Select the column of data to be used as the Gene Value from the drop down list or select [none]. We will use "Avg_LogFC_" for the the appropriate time point.
- Activate the Criteria Builder by clicking the New button.
- Enter a name for the criterion in the Label in Legend field.
- Choose a color for the criterion by left-clicking on the Color box. Choose a color from the Color window that appears and click OK.
- State the criterion for color-coding a gene in the Criterion field.
- A criterion is stated with relationships such as "this column greater than this value" or "that column less than or equal to that value". Individual relationships can be combined using as many ANDs and ORs as needed. A typical relationship is
[ColumnName] RelationalOperator Value
with the column name always enclosed in brackets and character values enclosed in single quotes. For example:
[Fold Change] >= 2 [p value] < 0.05 [Quality] = 'high'
This is the equivalent to queries that you performed on the command line when working with the PostgreSQL movie database. GenMAPP is using a graphical user interface (GUI) to help the user format the queries correctly. The easiest and safest way to create criteria is by choosing items from the Columns and Ops (operators) lists shown in the Criteria Builder. The Columns list contains all of the column headings from your Expression Dataset. To choose a column from the list, click on the column heading. It will appear at the location of the cursor in the Criterion box. The Criteria Builder surrounds the column names with brackets.
The Ops (operators) list contains the relational operators that may be used in the criteria: equals ( = ) greater than ( > ), less than ( < ), greater than or equal to ( >= ), less than or equal to ( <= ), is not equal to ( <> ). To choose an operator from the list, click on the symbol. It will appear at the location of the insertion bar (cursor) in the Criterion box. The Criteria Builder automatically surrounds the operators with spaces. The Ops list also contains the conjunctions AND and OR, which may be used to make compound criteria. For example:
[Fold Change] > 1.2 AND [p value] <= 0.05
Parentheses control the order of evaluation. Anything in parentheses is evaluated first. Parentheses may be nested. For example:
[Control Average] = 100 AND ([Exp1 Average] > 100 OR [Exp2 Average] > 100)
Column names may be used anywhere a value can, for example:
[Control Average] < [Experiment Average]
- After completing a new criterion, add the criterion entry (label, criterion, and color) to the Criteria List by clicking the Add button.
- For the wt data, you will create two criterion for each Color Set. "Increased" will be [wt_Avg_LogFC_<timepoint>] > 0.25 AND [wt_Pval_<timepoint>] < 0.05 and "Decreased will be [wt_Avg_LogFC_<timepoint>] < -0.25 AND [wt_Pval_<timepoint>] < 0.05. Make sure that the increased and decreased average log fold change values match the timepoint of the Color Set.
- For the Δash1 data, we do not have p values, so we will just consider up- and down-regulation of the Log Fold Changes for the individual timepoints.
- The buttons to the right of the list represent actions that can be performed on individual criteria. To modify a criterion label, color, or the criterion itself, first select the criterion in the list by left-clicking on it, and then click the Edit button. This puts the selected criterion into the Criteria Builder to be modified. Click the Save button to save changes to the modified criterion; click the Add button to add it to the list as a separate criterion. To remove a criterion from the list, left-click on the criterion to select it, and then click on the Delete button. The order of Criteria in the list has significance to GenMAPP. When applying an Expression Dataset and Color Set to a MAPP, GenMAPP examines the expression data for a particular gene object and applies the color for the first criterion in the list that is true. Therefore, it is imperative that when criteria overlap the user put the most important or least inclusive criteria in the list first. To change the order of the criteria in the list, left-click on the criterion to select it and then click the Move Up or Move Down buttons. No criteria met and Not found are always the last two positions in the list.
- Save the entire Expression Dataset by selecting Save from the Expression Dataset menu. Changes made to a Color Set are not saved until you do this.
- Exit the Expression Dataset Manager to view the Color Sets on a MAPP. Choose Exit from the Expression Dataset menu or click the close box in the upper right hand corner of the window.
- Save your .gex file to your flash drive (or other storage)
- Click here to download a zipped set of MAPPs with which to view your Expression Dataset. You will select one MAPP that you find interesting to include and interpret for your final lab report.
- Click here to download a zipped MAPP listing ASH1 targets from the YEASTRACT database, considering DNA-binding evidence only, for analysis and inclusion in your final lab report.
