User:Alexander T. J. Barron/Notebook/PHYC 307L Lab Notebook/finance notes
Day 1
SJK 16:40, 19 December 2008 (EST)

Hey Der, This looks really great, and I am really looking forward to looking at it some more. Sorry about the huge delay in me looking at it, but I hope to look at it some more after the semester grading is done. Thanks for taking on this project!
The topics of this lab were unbounded, so most of the work was in trying to narrow our project to a realizable goal. After exploring some deeper topics that led down unanswerable (and endless) philosophical and political paths we decided we must narrow our search. So we decided to set some goals, then choose a topic of finance that would lead to valuable exercises in the following:
- data analysis
- computational technique
- finance terminology
- historical perspective
We remembered a lab we did in PHYS 290 with Dr. Stephen Boyd where we analyzed stock data. We loaded said data to MATAB, then performed simple and exponential moving averages on it. This excercise gave us a bit of inspiration, or rather helped us to focus our topic search. After contacting Dr. Boyd about the source of his stock data, and discussing with Dr. Koch, our goal then eventually became the following:
Purpose of Our Finance lab
The purpose of this lab is to study rate growth in the stock market, we will do this by asking a question.
If one makes a ten year investment in the stock market, what should one expect, based on historical analysis, to be one's rate of growth?
Questions that come about from this question:
- What financial data/market would be a good indicator for such a broad question?
- Where do we get this data?
- How do we simulate "investment" with the historical data in hand?
- What does it mean to expect a rate of growth?
- Is there an average rate of growth, or maybe even a rate that fits some known distribution?
What we learned on the way
What we learned from our initial exploration:
Financial gurus have created market indicators called "indices" to chart the progress of sectors of the stock market. Well known market indices are the NASDAQ, the S&P 500, and the Dow Jones. A stock index is basically a summation of the stocks of a selected group of companies. The selection of course is chosen based on the purpose of the index, to follow a certain industry within the ecomomy.
We learned that these indices are created using two different methods:
- Price weighted: is just the average of the prices of all the stocks making up the index. An example is the Dow Jones Industrial Average which is a simple summation of the prices divided by the Dow jones "divisor", the number of component companies. In this way it is a true average.
- [math]\displaystyle{ \text{DJIA} = {\sum p \over d}, }[/math]
where p is the price of the shares and d is the # of companies.
- Market value-weighted: accounts for the size of each company making up the index such that price changes in smaller companies don't effect the index more than they should as compared to the bigger companies.
We found these methods very interesting and spent a considerable amount of time exploring this as a possible purpose of our lab. We considered making our own indices for fun, or making an index that would capture the trends of the recent financial crisis. We decided that this would be unnecessary and that we should use the indices already out there.
Another idea we pursued was calculation of net present value, and the comparison of investments at different times. We researched into net present value, with the idea in mind that we will calculate the true value of investing in US Treasury bonds over a period of time.
Net present value (NPV) is a comparison of a dollar today to a projected value for the same dollar at some point in the future. Present value is the value on a given date of a future payment or series of future payments, discounted to reflect the time value of money and other factors such as investment risk. A common model of present value is the compund interest formula that calculates how much money you will have in an account make a certain interest after a certain amount of time.
This led us to bonds. Maybe we could compare bonds with savings accounts, or other securities like stock. We ended up learning a little about bonds...
A bond is a loan in the form of a security. A security is defined as something fungible (exhangeable with itself like currency, oil, gold). However, a bond is not an equity like stock. Some bond vocabulary we learned:
- principle/nominal/face value: the ammount which the issuer pays interest, which has to be repaid in the end.
- issue price: the price the investor buys the bond when issued.
- maturity date: the time the issuer repays the nominal amount.
- yield: percent that measures cash return to owners of the bond.
- nominal yield: yearly total of interest paid to owner divided by principal face value of bond.
We might use our new knowledge of bonds and compare bonds yield rates to the average growth rate fo the stock market. Which is a higher growth investment? Obviously, this is a complicated question. The stock market may grow faster, but it falls faster too and is high risk compared to bonds (especially US treasury bonds). Therefore comparing stock to bonds is sort of silly but might prove to be a worthwhile comparison.
Day 2
We were still somewhat adrift regarding real lab-worthy content of our lab, so we leapt at Dr. Koch's idea to analyze randomly-generated time windows over the course of the DJIA. We initially chose 10-year windows in order to compare to a 10-year US security bond. When creating the code to do this, we ended up discussing whether we should take least-squares fits of each window, or to take 10-year "snapshots," which find the slope from the two stock prices at the endpoints of the window. Snapshots make sense in that a person investing during that exact time period would see exactly that rate of growth. Least-squares fits show more of a trend over the 10 years, so that someone who invested only 9 years, 10 months might see growth closer to the fit than the snapshot.
The code I generated on that day basically failed - I was tearing my hair out for a while, but I got it eventually. I ended up generating data for 10-, 20-, 30-, 40-, and 50-year windows, all with 100 randomly-generated iterations. My hypothesis is that the shorter windows will be more sensitive to small changes in the market, so their slopes will be more severe. Ideally, the number of iterations should be inversely proportional to the length of the window because the longer windows will naturally cover more data than the shorter. However, equal iteration counts make easier analysis.
Data Analysis
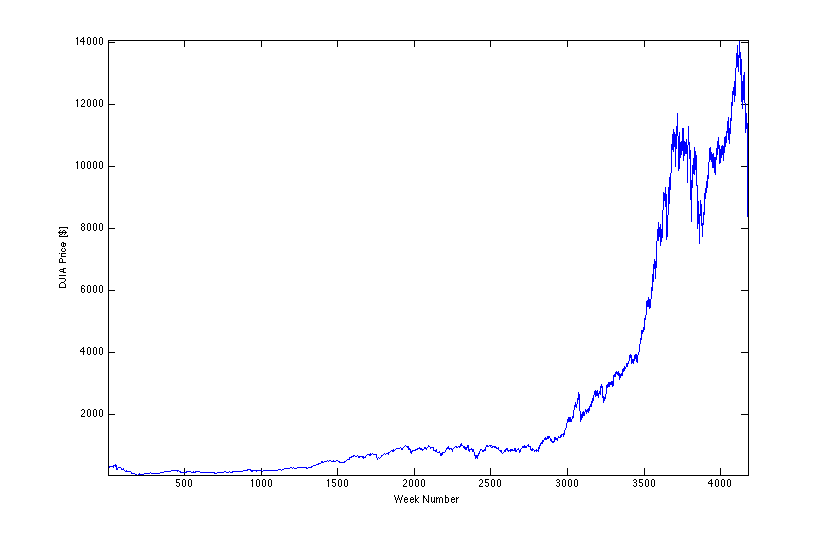
Data from Yahoo! Finance.
Ticker: ^DJI, weekly from 10/01/1928 to 10/27/08.
Using the least-squares fit provides a great opportunity to hone my error propagation skills (proven quite dull in my last attempt). SO!.... here is the rundown:
Each window will have an error according to these parameters, from the line-fitting help page:
[math]\displaystyle{ \ y=A+Bx }[/math]
[math]\displaystyle{ \sigma_B^2 = N \frac{\sigma_y^2}{\Delta_{fixed}} }[/math]
(I believe this is the same as 1/N * σy2 / σx2, where σx2 is the population variance of the experimental x values, not the variance of an individual x measurement.)
Since there is no error on the stock price measurements every week, I'll have to find the inferred error:
[math]\displaystyle{ \sigma_{y~inferred} =\sqrt{\frac {1}{N-2} \sum (y_i - A - Bx_i)^2} }[/math] [math]\displaystyle{ \mbox{,}~~~~~~~\mbox{recall,}~~ \chi^2 = \frac {1}{\sigma_y^2} \sum (y_i - A - Bx_i)^2 }[/math]
[math]\displaystyle{ \Delta_{fixed}=N \sum x_i^2 - \left ( \sum x_i \right )^2 }[/math] (This is actually N2 times the population variance of x...not sure if that helps in any kind of understanding, though.)
In my code, I utilized the above note on Δfixed.
To find the error on the mean of all 100 slope measurements, I use the linear-approximation method and add in quadrature:
[math]\displaystyle{ r_{avg} = \frac{1}{T} \times (r_1 + r_2 + ... +r_T) \longrightarrow \sigma_{r_{avg}} = \sqrt{(\frac{\partial r_{avg}}{\partial r_1} \sigma_{r_1})^2 + (\frac{\partial r_{avg}}{\partial r_2} \sigma_{r_2})^2 + ... + (\frac{\partial r_{avg}}{\partial r_T} \sigma_{r_T})^2} , }[/math]
[math]\displaystyle{ T = 100, \sigma_B \rightarrow \sigma_i }[/math]
[math]\displaystyle{ \downarrow }[/math]
[math]\displaystyle{ \sigma_{r_{avg}} = \frac{1}{100}\sqrt{{\sigma_{r_1}}^2 + {\sigma_{r_2}}^2 + ... + {\sigma_{r_T}}^2} }[/math]
| Slope Data [$/week] ± σravg | Sample Window | ||||||||||||||||||||||
|
|||||||||||||||||||||||
|
|||||||||||||||||||||||
|
|||||||||||||||||||||||
|
|||||||||||||||||||||||
|
|||||||||||||||||||||||





My gut is telling me that my error is off-base once again, but I don't see a flaw in my approach based on Dr. Koch's lectures and reference to Taylor.
Distribution?
My original plan was to fit probability-density plots with various distributions, Gaussian chief among them. Here are the results for each time window, 20 trials:
| 20 Iteration Probability Distribution | Fit Parameters | |
|
| |
|
| |
|
| |
|
| |
|
|





I think it is fairly obvious I need much more data to get an accurate picture of the distribution. Here goes for 500 trials:
| 500 Iteration Probability Distribution | Fit Parameters | ||
|
| ||
|
| ||
|
| ||
|
| ||
|
|










I chose the "best" fit from the log-likelihood value. Internet resources are almost all entirely cryptic regarding this quantity, but I believe that a higher value indicates a better fit. However, just eyeballing would suggest that I either need more iterations to truly analyze the data, or that none of the distributions correlate very well. Specifically, the larger-window averages seem to have "flat-topped" histograms, which none of the distributions provided models. There is an observable trend in the leftward-leaning "shoulder" of each histogram, which basically makes a Gaussian distribution out of the question. Both Nakagami and Log Normal take this lean into account. In truth, I think running thousands of iterations would give clearer results and take away the hills and valleys still prevalent in each histogram. Unfortunately, MATLAB has revealed its lack of speed to me- 10,000 iterations would take days to run.
Although I can fit these histograms marginally well with a known distribution, I don't think this means anything in a fundamental sense. According to Wikipedia, Nakagami created his distribution to analyze radio signals in his research, so comparing it with these histograms is frivolous. If one looks at the entire history of the DJIA used in this lab, lower slope dominates, correlating to the leftward-leaning shoulder on the histogram. It is gratifying, however, that I see a reflection in the processed data corresponding to what is evident in the raw data.
|
Code
%% Finance Lab
% Alexander Barron
% Junior Lab Fall 2008
close all, clear all;
%% Load Data
DJIAprice = csvread('DJIA28to03weekly.csv',1,6,[1 6 4177 6]);
DJIAprice = flipud(DJIAprice);
DJIAprice = DJIAprice.';
t = linspace(1,length(DJIAprice),length(DJIAprice));
% scrsz = get(0,'ScreenSize');
% figure('Position',[1 scrsz(4)/1.5 scrsz(3)/1.55 scrsz(4)/1.6]);
%
% plot(t,DJIAprice);
% axis tight;
% xlabel('Week Number');
% ylabel('DJIA Price [$]');
%% 20 Iterations
rav10vec = zeros(1,20);
rav20vec = zeros(1,20);
rav30vec = zeros(1,20);
rav40vec = zeros(1,20);
rav50vec = zeros(1,20);
rav10errvec = zeros(1,20);
rav20errvec = zeros(1,20);
rav30errvec = zeros(1,20);
rav40errvec = zeros(1,20);
rav50errvec = zeros(1,20);
for f=1:100;
%% 10-year windows
for j=1:100;
windstart10 = ceil(rand*(length(t)-520));
windend10 = windstart10 + 519;
windt10{j} = linspace(windstart10,windend10,520); % cell structure of
% randomly-
% generated 10-year
% time windows
windval10{j} = DJIAprice(windt10{j});
[linfit10{j},linfit10err{j}] = polyfit(windt10{j},windval10{j},1);
linval10{j} = linfit10{j}(1).*windt10{j}+linfit10{j}(2);
clear windstart10, clear windend10;
end
% figure('Position',[20 scrsz(4)/1.5 scrsz(3)/1.55 scrsz(4)/1.6]);
% randind=ceil(100*rand);
% plot(windt10{randind},windval10{randind},'b.');
% hold on;
% plot(windt10{randind},linval10{randind},'k--');
% axis tight;
% legend('DJIA price','Trend Line','Location','Best');
% title('10-year Window Example');
% ylabel('DJIA price');
% xlabel('Week Number');
%% 20-year windows
for j=1:100;
windstart20 = ceil(rand*(length(t)-1040));
windend20 = windstart20 + 1039;
windt20{j} = linspace(windstart20,windend20,1040);
windval20{j} = DJIAprice(windt20{j});
[linfit20{j},linfit20err{j}] = polyfit(windt20{j},windval20{j},1);
linval20{j} = linfit20{j}(1).*windt20{j}+linfit20{j}(2);
clear windstart20, clear windend20;
end
% figure('Position',[40 scrsz(4)/1.5 scrsz(3)/1.55 scrsz(4)/1.6]);
% randind2=ceil(100*rand);
% plot(windt20{randind2},windval20{randind2},'b.');
% hold on;
% plot(windt20{randind2},linval20{randind2},'k--');
% axis tight;
% legend('DJIA price','Trend Line','Location','Best');
% title('20-year Window Example');
% ylabel('DJIA price');
% xlabel('Week Number');
%% 30-year windows
for j=1:100;
windstart30 = ceil(rand*(length(t)-1560));
windend30 = windstart30 + 1559;
windt30{j} = linspace(windstart30,windend30,1560);
windval30{j} = DJIAprice(windt30{j});
[linfit30{j},linfit30err{j}] = polyfit(windt30{j},windval30{j},1);
linval30{j} = linfit30{j}(1).*windt30{j}+linfit30{j}(2);
clear windstart30, clear windend30;
end
% figure('Position',[60 scrsz(4)/1.5 scrsz(3)/1.55 scrsz(4)/1.6]);
% randind3=ceil(100*rand);
% plot(windt30{randind3},windval30{randind3},'b.');
% hold on;
% plot(windt30{randind3},linval30{randind3},'k--');
% axis tight;
% legend('DJIA price','Trend Line','Location','Best');
% title('30-year Window Example');
% ylabel('DJIA price');
% xlabel('Week Number');
%% 40-year windows
for j=1:100;
windstart40 = ceil(rand*(length(t)-2080));
windend40 = windstart40 + 2079;
windt40{j} = linspace(windstart40,windend40,2080);
windval40{j} = DJIAprice(windt40{j});
[linfit40{j},linfit40err{j}] = polyfit(windt40{j},windval40{j},1);
linval40{j} = linfit40{j}(1).*windt40{j}+linfit40{j}(2);
clear windstart40, clear windend40;
end
% figure('Position',[80 scrsz(4)/1.5 scrsz(3)/1.55 scrsz(4)/1.6]);
% randind4=ceil(100*rand);
% plot(windt40{randind4},windval40{randind4},'b.');
% hold on;
% plot(windt40{randind4},linval40{randind4},'k--');
% axis tight;
% legend('DJIA price','Trend Line','Location','Best');
% title('40-year Window Example');
% ylabel('DJIA price');
% xlabel('Week Number');
%% 50-year windows
for j=1:100;
windstart50 = ceil(rand*(length(t)-2600));
windend50 = windstart50 + 2599;
windt50{j} = linspace(windstart50,windend50,2600);
windval50{j} = DJIAprice(windt50{j});
[linfit50{j},linfit50err{j}] = polyfit(windt50{j},windval50{j},1);
linval50{j} = linfit50{j}(1).*windt50{j}+linfit50{j}(2);
clear windstart50, clear windend50;
end
% figure('Position',[80 scrsz(4)/1.5 scrsz(3)/1.55 scrsz(4)/1.6]);
% randind5=ceil(100*rand);
% plot(windt50{randind5},windval50{randind5},'b.');
% hold on;
% plot(windt50{randind5},linval50{randind5},'k--');
% axis tight;
% legend('DJIA price','Trend Line','Location','Best');
% title('50-year Window Example');
% ylabel('DJIA price');
% xlabel('Week Number');
%% Slope Mean
slopevec10 = zeros(1,100);
slopevec20 = zeros(1,100);
slopevec30 = zeros(1,100);
slopevec40 = zeros(1,100);
slopevec50 = zeros(1,100);
for j=1:100;
slopevec10(j) = linfit10{j}(1);
slopevec20(j) = linfit20{j}(1);
slopevec30(j) = linfit30{j}(1);
slopevec40(j) = linfit40{j}(1);
slopevec50(j) = linfit50{j}(1);
end;
rav10vec(f) = mean(slopevec10)
rav20vec(f) = mean(slopevec20);
rav30vec(f) = mean(slopevec30);
rav40vec(f) = mean(slopevec40);
rav50vec(f) = mean(slopevec50);
%% Error Propogation
% inferred error for each fit...this is huge...
deg10 = linfit10err{j}.df; % degrees of freedom for each window
deg20 = linfit20err{j}.df;
deg30 = linfit30err{j}.df;
deg40 = linfit40err{j}.df;
deg50 = linfit50err{j}.df;
degsigstart = 0; % representing sigma inferred times d. o. f.
% and setting up for sum of chi^2*sigy^2
degsig10 = zeros(1,100);
degsig20 = zeros(1,100);
degsig30 = zeros(1,100);
degsig40 = zeros(1,100);
degsig50 = zeros(1,100);
deltafixed10 = zeros(1,100);
deltafixed20 = zeros(1,100);
deltafixed30 = zeros(1,100);
deltafixed40 = zeros(1,100);
deltafixed50 = zeros(1,100);
for j=1:100; % accessing all above structures for necessary data
% to properly propogate a plethora of faux pas
% (errors...)
for k=1:520;
degsig10(j) = degsigstart +... % sum of chi^2*sigy^2
(windval10{j}(k) - linfit10{j}(2) - linfit10{j}(1)*windt10{j}(k))^2;
end;
deltafixed10(j) = 520*(519)*var(windt10{j}); % correcting MATLAB's version
% of population variance
for k=1:1040;
degsig20(j) = degsigstart +...
(windval20{j}(k) - linfit20{j}(2) - linfit20{j}(1)*windt20{j}(k))^2;
end;
deltafixed20(j) = 1040*(1039)*var(windt20{j});
for k=1:1560;
degsig30(j) = degsigstart +...
(windval30{j}(k) - linfit30{j}(2) - linfit30{j}(1)*windt30{j}(k))^2;
end;
deltafixed30(j) = 1560*(1559)*var(windt30{j});
for k=1:2080;
degsig40(j) = degsigstart +...
(windval40{j}(k) - linfit40{j}(2) - linfit40{j}(1)*windt40{j}(k))^2;
end;
deltafixed40(j) = 2080*(2079)*var(windt40{j});
for k=1:2600;
degsig50(j) = degsigstart +...
(windval50{j}(k) - linfit50{j}(2) - linfit50{j}(1)*windt50{j}(k))^2;
end;
deltafixed50(j) = 2600*(2599)*var(windt50{j});
end;
sigpinf10 = sqrt(degsig10./deg10);
sigpinf20 = sqrt(degsig20./deg20);
sigpinf30 = sqrt(degsig30./deg30);
sigpinf40 = sqrt(degsig40./deg40);
sigpinf50 = sqrt(degsig50./deg50);
ratesig10 = sqrt(520.*sigpinf10.^2./deltafixed10);
ratesig20 = sqrt(1040.*sigpinf20.^2./deltafixed20);
ratesig30 = sqrt(1560.*sigpinf30.^2./deltafixed30);
ratesig40 = sqrt(2080.*sigpinf40.^2./deltafixed40);
ratesig50 = sqrt(2600.*sigpinf50.^2./deltafixed50);
rav10errvec(f) = (1/100).*sqrt(sum(ratesig10.^2)); % adding error contributions
rav20errvec(f) = (1/100).*sqrt(sum(ratesig20.^2)); % of 100 slope fits in
rav30errvec(f) = (1/100).*sqrt(sum(ratesig30.^2)); % quadrature
rav40errvec(f) = (1/100).*sqrt(sum(ratesig40.^2));
rav50errvec(f) = (1/100).*sqrt(sum(ratesig50.^2));
end;
