Testing Report 10/1/2014
Export Information
Version of GenMAPP Builder:2.0b81
Computer on which export was run: Dahlquist lab computer cerevisiae
Postgres Database name:Vibrio
UniProt XML filename:uniprot-organism%3A243277+keyword%3A1185
- UniProt XML version (The version information can be found at the UniProt News Page):UniProt release 2014_08 (September 3, 2014)
- Time taken to import:2.59 minutes
GO OBO-XML filename:go_daily-termdb.obo-xml
- GO OBO-XML version (The version information can be found in the file properties after the file downloaded from the GO Download page has been unzipped):10/1/2014 3:06 pm
- Time taken to import:6.42 minutes
- Time taken to process:4.78 minutes
GOA filename: 46.V_cholerae_ATCC_39315.goa
- GOA version (News on this page records past releases; current information can be found in the Last modified field on the FTP site):9/29/14 5:47:00 PM
- Time taken to import: 0.05 minutes
Name of .gdb file: Vc-Std_20141001.gdb
- Time taken to export .gdb:Unknown
- Upload your file and link to it here. Vc-Std 20141001.gdb
- Owner: Dahlquist
Note:
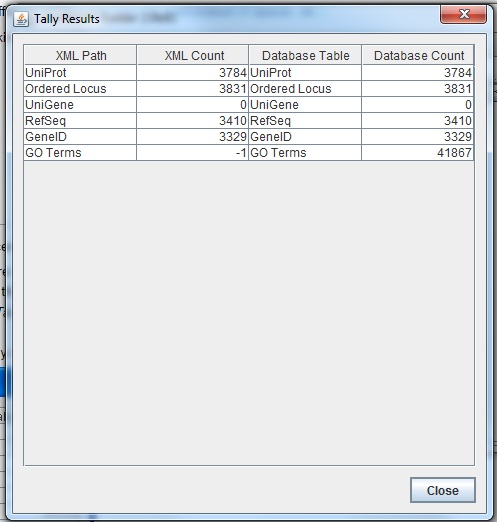
TallyEngine
Run the TallyEngine in GenMAPP Builder and record the number of records for UniProt and GO in the XML data and in the PostgreSQL databases (or you can upload and link to a screenshot of the results).
Using XMLPipeDB match to Validate the XML Results from the TallyEngine
Follow the instructions found on this page to run XMLPipeDB match.
Are your results the same as you got for the TallyEngine? Why or why not?
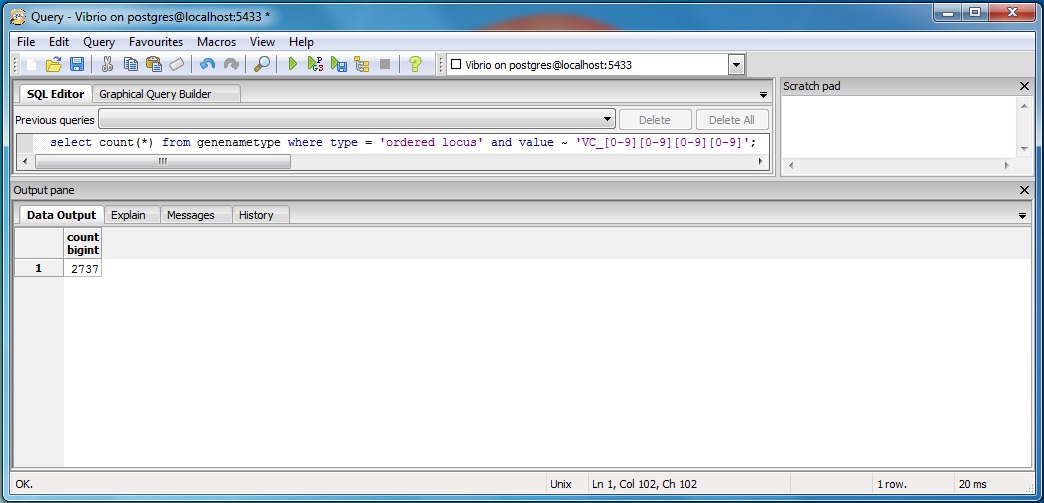
Using SQL Queries to Validate the PostgreSQL Database Results from the TallyEngine
Follow the instructions on this page to query the PostgreSQL Database.
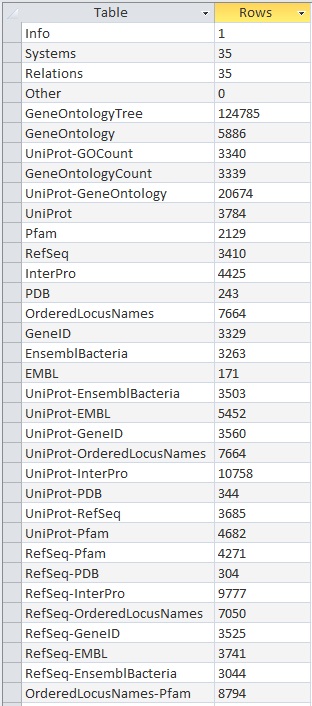
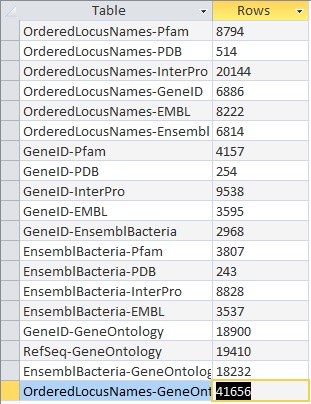
OriginalRowCounts Comparison
Within the .gdb file, look at the OriginalRowCounts table to see if the database has the expected tables with the expected number of records. Compare the tables and records with a benchmark .gdb file.
Benchmark .gdb file: (for the Week 9 Assignment, use the "Vc-Std_External_20101022.gdb" as your benchmark, downloadable from here.
Copy the OriginalRowCounts table and paste it here:
Note:
Visual Inspection
Perform visual inspection of individual tables to see if there are any problems.
- Look at the Systems table. Is there a date in the Date field for all gene ID systems present in the database?
- Open the UniProt, RefSeq, and OrderedLocusNames tables. Scroll down through the table. Do all of the IDs look like they take the correct form for that type of ID?
Note:
.gdb Use in GenMAPP
Note:
Putting a gene on the MAPP using the GeneFinder window
- Try a sample ID from each of the gene ID systems. Open the Backpage and see if all of the cross-referenced IDs that are supposed to be there are there.
Note:
Creating an Expression Dataset in the Expression Dataset Manager
- How many of the IDs were imported out of the total IDs in the microarray dataset? How many exceptions were there? Look in the EX.txt file and look at the error codes for the records that were not imported into the Expression Dataset. Do these represent IDs that were present in the UniProt XML, but were somehow not imported? or were they not present in the UniProt XML?
Note:
Coloring a MAPP with expression data
Note:
Running MAPPFinder
Note:
Compare Gene Database to Outside Resource
The OrderedLocusNames IDs in the exported Gene Database are derived from the UniProt XML. It is a good idea to check your list of OrderedLocusNames IDs to see how complete it is using the original source of the data (the sequencing organization, the MOD, etc.) Because UniProt is a protein database, it does not reference any non-protein genome features such as genes that code for functional RNAs, centromeres, telomeres, etc.
Note:

{kind=link}
{kind=link}
{kind=link}
{kind=link}