Moore Notes 7 6 15
From OpenWetWare
Jump to navigationJump to search
Group Call
- Participants: Katie, Josh
- Progress report submitted
- ShotMAP paper submitted
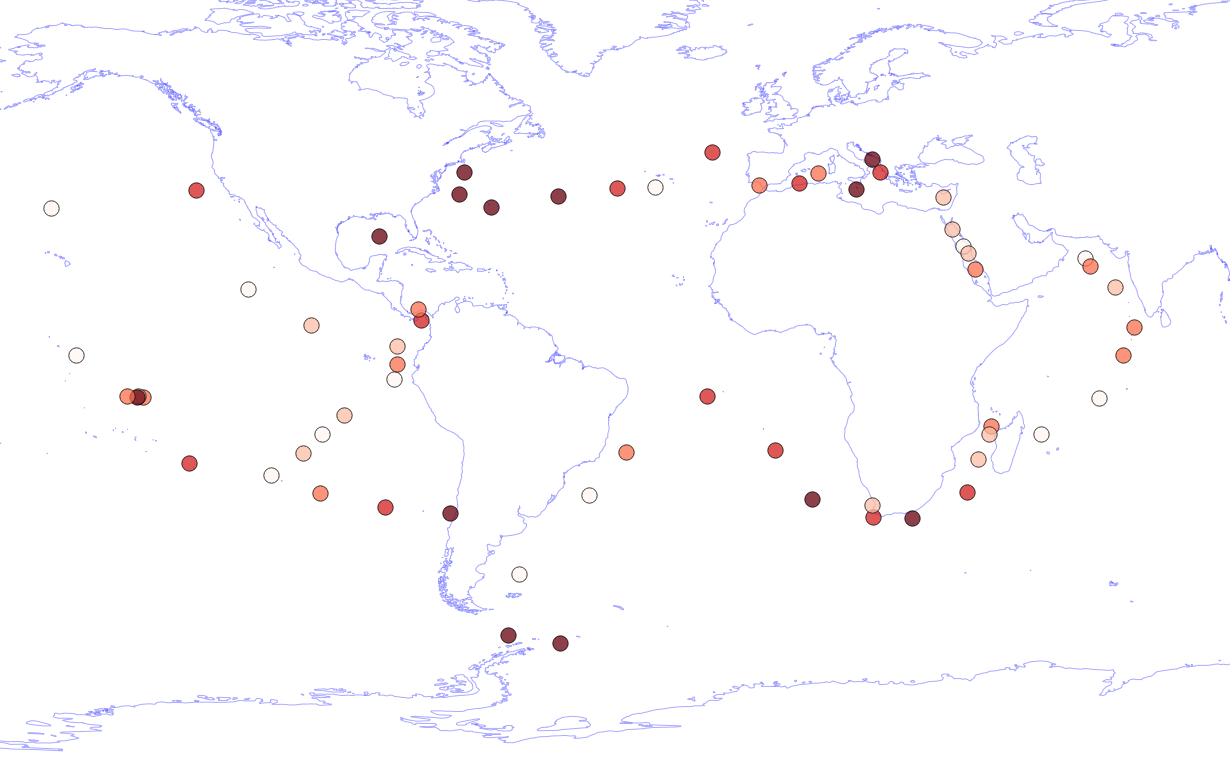
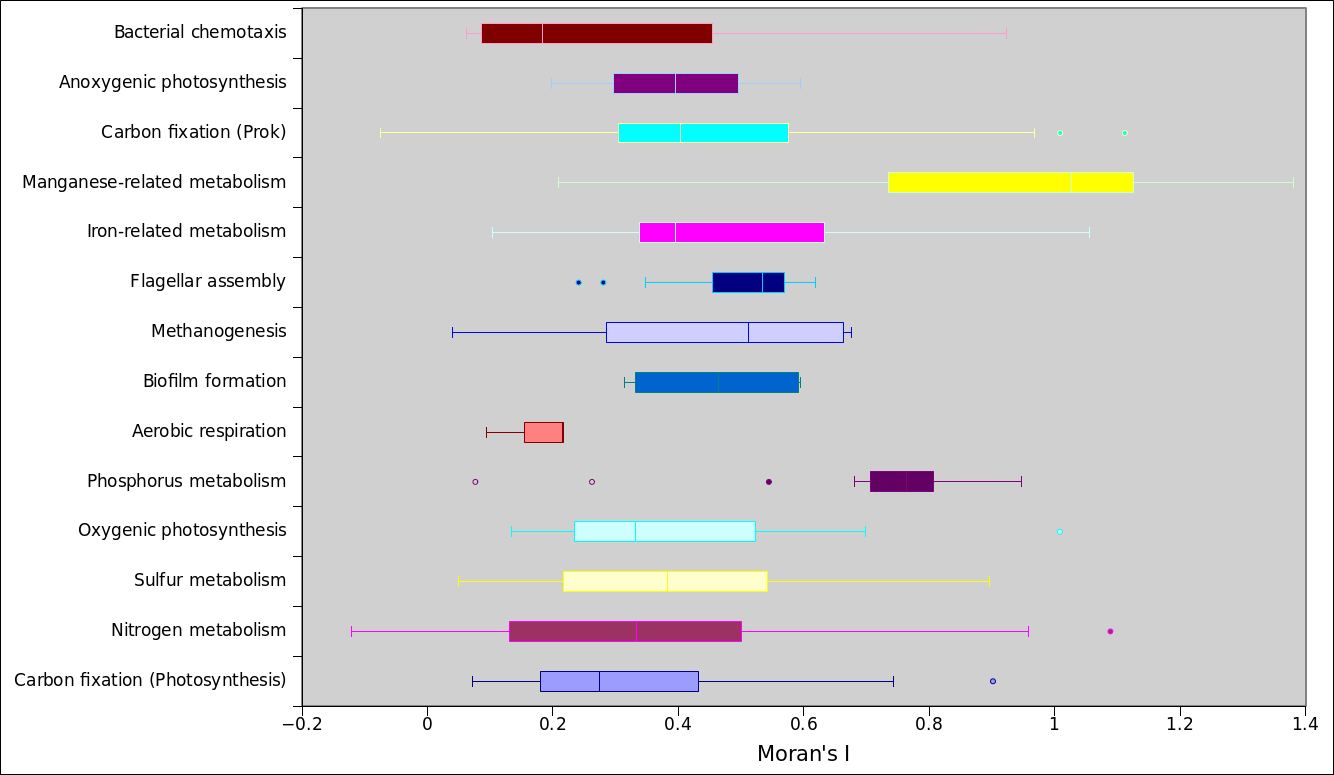
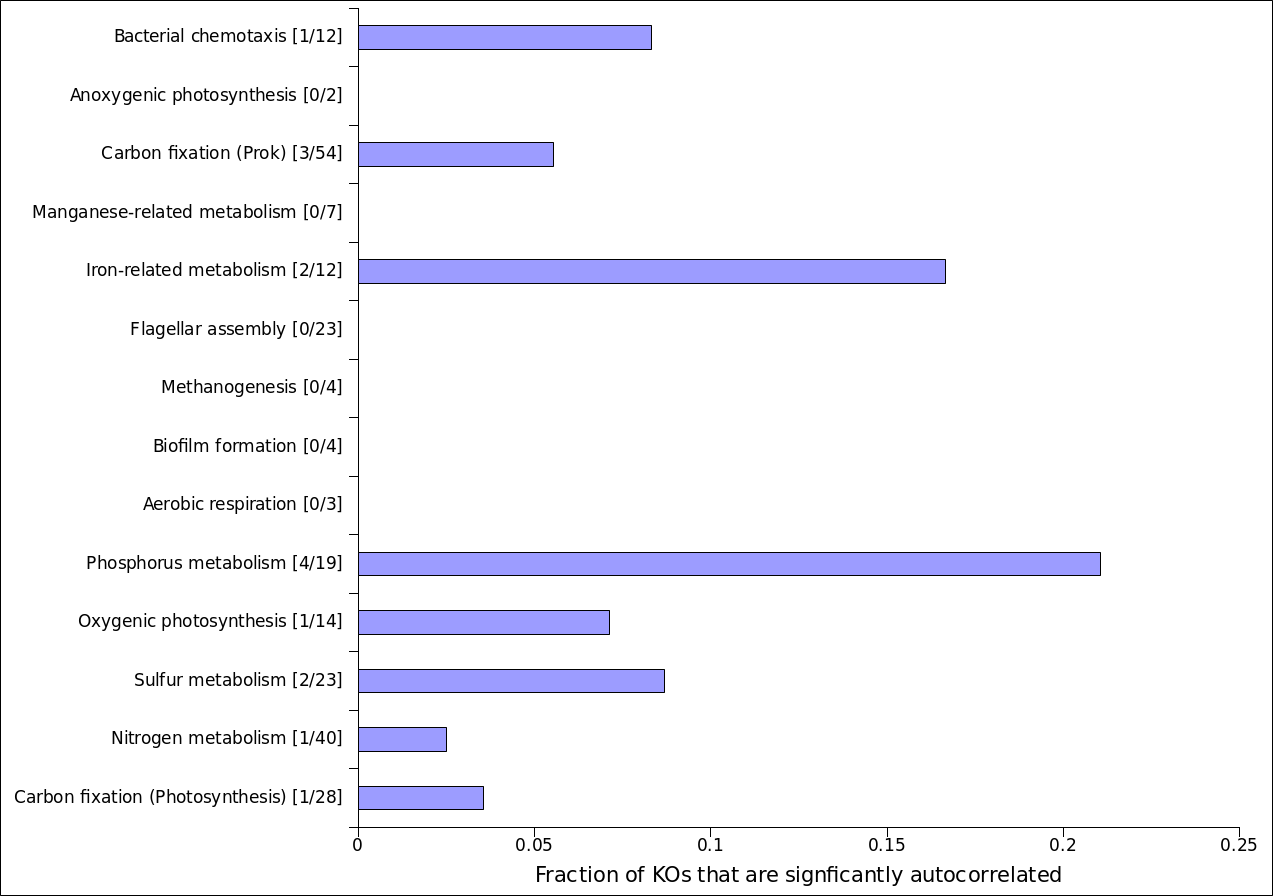
- Josh: Tara Oceans - preliminary analyses
- Spatial autocorrelation measured by Morans I statistic
- Methods for quantifying KO abundance
- Fragment recruitment to assembly based database (Tara Oceans) versus classification to a protein database
- Patrick: How about first assembly, then genomic protein db? Stephen: humann2 does this with genome db then genomic protein db
- Tom: compare to RPKG values with AGS normalization
- Patrick/Stephen: What about abundance? Or absolute abundance (i.e., concentration)? Josh: flow cytometry data
- Unmapped reads can create or destroy spatial autocorrelation (look at classification rates)
- Fragment recruitment to assembly based database (Tara Oceans) versus classification to a protein database
- Comparing to taxonomic distributions
- Sarah's methods
- Patrick has Dongying's PD metric for all KOs
- KOs versus modules
- Katie: aggregate data for module before modeling, computing autocorrelation
- Stephen: look at humann paper (e.g., minPath)
- Stephen: Look at gene content and strain level variation
- Presence / absence analysis
- Pollard lab summer intern: Kit Tse
- Spatial autocorrelation
- Next call in two weeks: Stephen
- Metaquery tool
- Strain level variation

{kind=link}
{kind=link}
{kind=link}